The AIDs data with which we’ve been working and pivot tabling – that is, multi-region by multi-year breakouts of the epidemic, e.g.:

snuggly dovetails with Sparklines, Edward Tufte’s mini-charting fillip that Excel enfolded into its 2010 release (for some deep background on all this, see Tufte’s discussion). Sparklines portray but one row’s worth of data each, locking a range-hugging stream of charts into standard, address-bearing cells:

You’ll note the Sparklines’ presentational gauntness – their label-free axes and Spartan décor, and no; you wouldn’t slap a Sparkline on your bosses desk, or give it pride of place in your firm’s annual report. But the Sparklines’ taciturnity supposes a method to their madness: the barebones isolation of data trajectories alone enforce a like-for-like serial scan down the column, a rhythm of perusal that frames a big comparative picture down the rows. Sparklines aren’t pretty, then, but their very banality sharpens the point they try to communicate. And they’re easy to construct.
By way of exemplification we can work with the UNAIDS workbook referenced in the previous post, and put together a pivot table as follows:
Row Labels area: Region
Column Labels area: Year
Values: Estimated number of Children newly infected (or however you’ve titled this field; see last week’s post).
(Note that you should filter the Western and Central Europe and North America row out of Row Labels, in view of its preponderance of empty data cells for the years 1990-2010.)
Now on to the Sparklines (remember that the feature debuted with the 2010 release). Click the Insert tab and observe the three Sparklines options stocking its button group. Click Line, thus triggering the Create Sparklines dialog box and its request for two bits of information:

Data range asks you to earmark the range of contributory data from which the Sparklines will be drawn. That range – really a set of mini-ranges – must comprise data only, and need exclude any data point or axis labels. In my pivot table that range blocks out B5:W14, each row of which is going to spur a Sparkline all its own. Thus I’m going to identify X5:X14, the range that immediately adjoins the data to their right. Click OK, and the Sparklines you see two screen shots back should fill the range.
Again the peculiar, albeit limited, virtues of Sparklines beg your attention. The serial iteration of the lines casts the data into an irresistibly comparative mode, reporting each region’s AIDS totals in a kind of visual arpeggiation. Note the near-straight-line ascent of the disease figures for the Middle East and North Africa region, held up against the curvilinear bend of Sub-Saharan Africa, and so on.
Those trajectories point up an important, but changeable, default setting of Sparklines. You’ll note the Sub-Saharan numbers far exceed those of Middle East-North Africa, but each Sparkline scales its curve against the data in its row alone, abjuring any global, range-wide absolute set of values. To see what I mean, click anywhere among the Sparklines. Note first of all that all the Sparklines are selected, because Excel assumes any formatting overhauls of the lines are to be implemented en masse. Note in turn that the Sparkline Tools tab bursts on screen; click its Design tab > Axis in the Group button group and you’ll see:

Note the Automatic for Each Sparkline default, sizing the vertical axis to each row’s values. That selection is plainly to be preferred here, because the pivot table’s Global totals will necessarily overwhelm those of the companion rows; clicking the Same for All Sparklines in the Vertical Axis Maximum Value Options area will run all the lines through an identical axis maximum, contorting the results:

In any case, you’ll want to play around with other Sparkline variations, e.g., particularly the Show button group and its point possibilities. For example, select the Sparklines and tick the High and Low point boxes:

Many other modifications are relatively self-evident, e.g, the style and color options. The Ungroup command will disperse the Sparklines, allowing the user to impose formatting remakes upon particular lines, but given their presentational of-a-piece character, you’re not likely to invest in this strategy.
Note in addition that if you drag the current Data values entry away and replace it with any of the many other AIDs data parameters the Sparklines will naturally, and immediately, redraw themselves, resonating to the insurgent values now place. (But note that if you instate a new set of values in the Data values area Excel may register these in Count, as opposed to Sum mode, something you’ll then have to change, along with their number formatting.)
And nothing stops you from resizing the Sparklines – only here you need to heighten a row or widen a column to do so, in lieu of dragging a typical chart’s borders.
There’s one final Sparkline capability worth expounding- the three Sparkline types, one of which – Line – we’ve reviewed here in some detail. The Column possibility emulates the garden-variety Column chart motif, in our case massing the data points into glacial monoliths:

The Win/Loss type is something else again, however, and can’t be properly directed to our data. Commensurate with its name, Win/Loss construes its data in brute binary terms, resting any positive value atop a virtual horizontal axis, and slipping any negatives beneath it.
To illustrate – if I chart a team’s wins and losses across a season and accompany the outcomes with a simple IF statement issuing 1 for a win, and -1 for a loss, e.g.:
![]()
The Win/Loss Sparkline will depict that second row of data thusly:
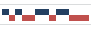
And if you click through the Sparkline Tools Design tab > Axis > Horizontal Axis Options > Show Axis sequence, you’ll get

That is, an actual horizontal axis centers itself across the Sparkline.
Thus if you need to subject your data to row-by-row scrutiny, Sparklines hold out a neat, practicable means for charting the numbers, adumbrating a big picture via a range of small ones. So start the picture-taking.

Leave a comment