Transparency, it’s wonderful – when it’s transparent. In fact, however, if that informational property is openly put in place but compromised at the same time by data that suffers from its own brand of opacity, then you have a problem – at least an analytical, if not political one.
Put more…transparently, it means that if the information so freely disclosed isn’t technically sound, the view gets dimmed, all the good-government intentions notwithstanding.
Case in point: the UK parliamentary expense data recounted by the Guardian and sourced in the first instance on the Independent Parliamentary Standards Authority web site(click the Data Downloads link), and these workbooks in particular (some field names are defined and explained here):
UK taxpayers – a coterie which seems to include yours truly – will be happy to audit the trail of requisitions upon which their elected officials have tread, and a good deal of the evidence is here. The question that could be asked is about their quality.
Turning first to the AnnualisedExpenseData (British spelling, note) sheet, you won’t need me to duly note the gathering of MP (Member of Parliament) Names into one cell, and sorted by first name. One might be pleased to leave that reversal of the conventional data wisdom alone, but if in fact you insist on a by-the-book, second name sort ordering you’ll have to think about it. If you reach for the Text to Columns tool and plan on parsing the MP names by their space separator (see the post) remember that you’ll need to clear out two blank columns here to the right of the original field, because text-to-columns data reassignments overwrite existing information in contiguous columns and you need two additional columns here because three MPs have three names each, a lovely complication that could be relieved by a rather enormous formula we haven’t the space to describe here. The realpolitik alternative, apart from relenting to the current names arrangement? Here’s one:
- Insert a column between columns A and B. Call it Last Name.
- Copy the contents of A to what is now column B.
- Select the names in the B column (B2:B65) and conduct the following Find and Replace:
Find: *[space]
Replace: leave blank
That device should deposit a precipitate of last names only in B. The Find-Replace seeks out all initial text up to, and including, the first space (the asterisk signifyies a wild-card search term), and replaces these with absolutely nothing. The remainder – last names only. Now feel free to sort by column B.
Now launch a fast scan of all the monetary data. If your antennae are pitching and yawing you’ve tuned into the right frequency, because all the numbers have been aligned left, the hallmark gauge of a text format. But we’re in luck. If you enter
=COUNT(D2:D658)
In cell D659 and copy the expression across all the number-bearing columns (ignore the results’ current format) you’ll get 657 every time, authenticating the numeric status of all these entries. Whew. You may still want to realign all these expense figures right, though, after which you could start to think about what one could make of them (an absence of MP party affiliations impairs the analytical prospects here, to be sure).
The second sheet – expense parliament 2013-14 – should prove more forthcoming, as it specifies, categorizes, and dates each expense item, thus conducing toward some interesting aggregations. You could, for example, splash out this pivot table:
Row Labels: Expense Type
Values: Amount Claimed (try sum and/or average, formatted to two decimals and with commas, or the 1000 separator, as Excel insists on calling it)
Amount Claimed (count)
(The below shot excerpts the whole.)

(You may note by the way that the Status column declares 10576 of the 10580 expense requests were paid in full).
In any case, once you’ve autofit the columns you could delete the Year column, containing as it does the undifferentiated 13_14 indication. But apart from another instance of first -name-first rendering of MP names another, familiar spectre haunts the data as well, one before which of which I need to issue a mea culpa of sorts. You may recall that my August 15 post on the massive UK food-inspection data decried the apparent fact that all dates featuring a day number greater than 12 presented themselves as text. I was somehow, and largely, wrong about that, in large measure because my grizzled laptop was set to the American date protocol, even as the data are expressed in European month-first syntax.
If you enter
=COUNT(B2:B10581)
in cell B10582, assuming it’s your B column that’s storing the date data, you’ll return 5132. Remember that COUNT only ticks cells containing numeric data, and as such it appears as if half the cells in B are something other than numeric – namely, text. Yet if you make way for a new column, say between B and C, call it Month and enter in C2
=MONTH(B2)
and copy it all the way down, you’ll discover that the month is realized for each and every B entry – as if each and every one of these were duly quantified, and not all of them really are, as our previous COUNT demonstrated. Moreover, the dates can’t be grouped, befitting data at least some of whose records are text-stamped.
I can’t authoritatively explain this inconsistency – namely why half the dates in B are reckoned as text (the Number Format field in the Number button group call them General, imputing them clear textual characteristics), and yet yield actual months when subject to the above unction. Suggestions, anyone? (See also my March 7 post for an account of a similar issue.)
But in any case, because the numbers do seem to work, more or less, you can easily push through a pivot table such as this one:
Row Labels: Month
Values: Amount Claimed (sum, formatted to two decimal points and a comma):

Hmmm. So anarchic is the monthly variation in expense claims that my primeval uncertainty about the date data churns anew – particularly after essaying this pivot table:
Row Labels: Month
Values: Month (count)

Half the expense claims were apparently filed in April, the month in which the British tax year culminates. In addition, if you substitute DAY for MONTH in the C column (and rename the field correspondingly) and run this table through the machinery:
Row Labels: Day
Values: Day (count)
You’ll see
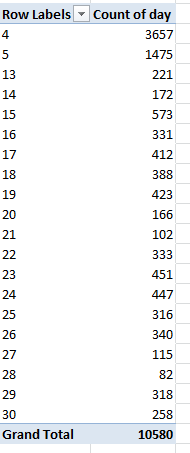
That is, a massive lopsiding toward the 4th and 5th days of the month – and absolutely no expenses claimed on the 31st of any month, besides.
Are these overwhelming monthly and daily skews some quaint British quirk of parliamentary scheduling? I doubt it, but let me ask my wife – she’s British. Be that as it may, maybe we have some kind of story here, or maybe we have nothing at all. In the meantime, I’m on holiday next week– but I need to think about all this. Move to adjourn.




