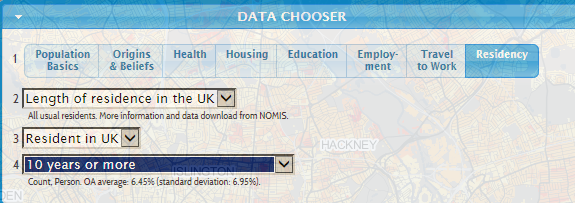
Sorry to butt in in the middle of breakfast/lunch/dinner (tick one – I’m requesting your location just once, and my intentions are cookie-free), but allow me to ask: if a web site makes its data – the same data – available in both spreadsheet and PDF incarnations, what are we being told? It seems to me that the latter possibility speaks to the former; that is, the shipping of information into a read-only, do-not-touch mode suggests the other shipment is meant to be used.
One man’s opinion; and having so opined, I took my self-satisfied take on the matter to the data depot in the European Union’s Eurostat site, the statistical office for that far-flung association. There’s a lot of stuff in there; climb its tree structure and you’ll come away with all manner of facts and figures and nuts and bolts about member nations, a great deal of which (perhaps even all) clothe themselves in spreadsheet raiment. And again for seekers of alternatives, a good many of these parcels of stuff can come to you in PDF suit-ups too.
And so I shot an arrow into the air, and it came down upon this spreadsheet
Eurostat_Table_guest establishments
(It’s original name isn’t nearly as graceful)
and headed in row 1 “Number of establishments and bed-places by NUTS 2 regions”, that pun-evocative acronym abbreviating Nomenclature of territorial units for statistics (look here for more), a vocabulary for hierarchically tiering EU territories by are.
In fact the downloads offer themselves to us thusly:
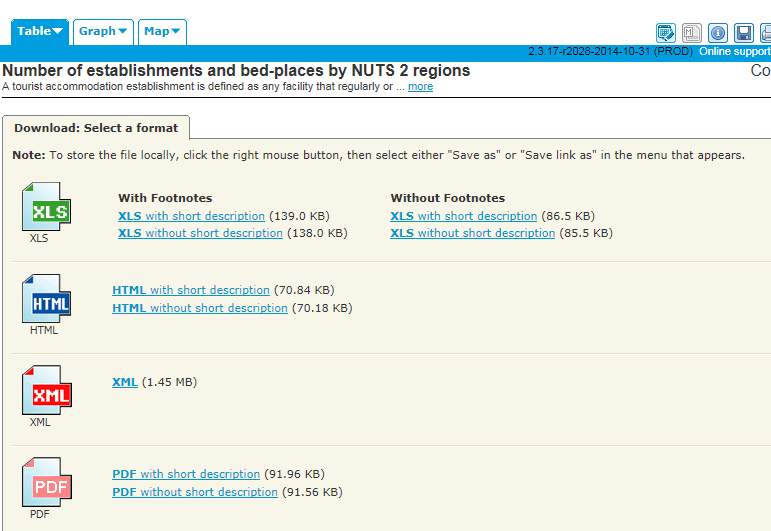
For starters, at least, I went for the XLS With Footnotes and short description, the workbook I’ve linked above.
Once you’ve auto-fit the columns (and as usual, the spreadsheet author hasn’t ) you’ll understand that rows 1 and 2 have to be pushed away from the data below with your true-blue blank row in between, as does 321, directly beneath the cell that among others names the Batman region (face it – you can’t help but admire my comedic restraint here). Next lower yourself into the data and think about the colons (e.g. row 139), that plant data-not-available markers all over the sheet. True, a replacement zero wouldn’t work here, representing as it would an authentic, quantified data point; but still, the labels are data weeds in a field otherwise marked out for values (and hold on to that thought).
But then there’s column C, and E, and G, and all those other empty corridors elbowing their way between the yearly numbers. Were these vacuities nothing but nothing, that is, airy space-makers between the data, we could simply delete them. But in fact the columns aren’t quite all empty, and have after all received a marching order. Remember my download asked for a workbook with footnotes somewhere in the workbook, even as I couldn’t quite fathom what that ask was going to deliver. It turns out that C, E, and G (I know; sounds like a major chord) and their compatriots have reserved their spaces for those very footnotes. Look for example at S130:S133 and their (u) entries; and if you look in turn back to what should now be row 322, its (u) explication, flagging a datum of low reliability, reads loud and clear.
And those largely but not wholly unattended footnote columns really mean well, because had the (u)s been made to cling to the values they footnote in their several cells, the value would have regressed to a text standing as a result, and would have repelled their data-purporting charge. Thus the sheet designer has rightly put the footnote-labels in their place – a place at a decisive remove from the numbers to which they’re keyed, in a column all their own. And yet the colons, themselves footnoted in row 322 as well, punctuate the columns of the values, albeit in otherwise unoccupied cells.
But cavils aside, what is the analyst to do with those footnote-spattered columns? How, for example, can a pivot table look past those extraneous, heartily non-contributory soft spots in the data set, and succeed in doing something manageable with the whole potpourri?
I think it can, by doing something exceedingly simple. How about naming the footnote columns? Once named, the columns advertise themselves as bona fide fields, however sparse, which can be then be properly ignored by the pivot tabler who wants to study only the annual numbers in the year fields.
Simple indeed, but putting new fields into play won’t complete the assignment. You’ll still need to do something about the colons, and because they’re sprinkled among the data-toting year columns, that something won’t be our standard sort-them-to-the-bottom-and-jab-in-an-empty-row patch, a nice but futile try here that would continue to leave colons above the bottom of the data by which you sorted in many of the other columns, by which you hadn’t sorted. Better here, then, might be a find and replace, in which the colons could be overwritten by zeros. Those numeric replenishers would at least restore some numeric standing to the cells, and so qualifying the data to run through their quantitative paces, including some grouping activity. Again, however, the zeros won’t be entirely truth-telling, as the NUT in question will be understood to have no guesting places, when in fact we don’t really know if they do or not.
The larger question, then, is what we do with data of the NA kind, however labelled. Another alternative here, then: find the colons and replace with say, the number 1,000,000, sort the numbers ascendingly, and hammer in the blank row right there. That is, a prudent surrender. There isn’t much else you can do with records that don’t know what’s in their fields.
I also feel obliged here to return the discussion to the field-item disquisition I’ve conducted on these pages, and the analytically advisable demotion of the year fields to item status, all rounded up beneath one, grand field.
And the plea to fairness again obliges me to begin to close the circle and track back to Eurostat’s square-one download options. Had I downloaded the data Without footnotes, I would have spread this sheet before me instead (in excerpt):
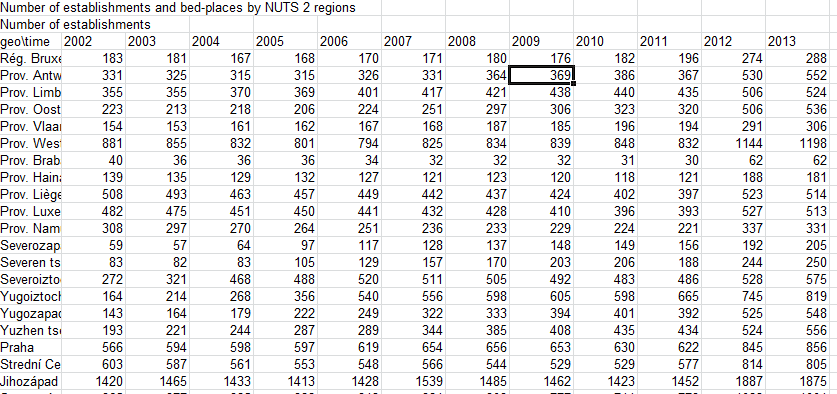
And that looks more like it, doesn’t it? But we still have those colons, don’t we?
But please – go back to breakfast/lunch/dinner. And sorry about the coffee spill – dry cleaning should get it out. Don’t forget to bill me.