Well, give me this: I’ve been trying. I’ve put the data quality questions I put to you in last week’s railroad accidents post to the parties of the first part, the Federal Railway Association, and the rest has been silence – at least so far, apart from the auto-responses that, if nothing else, have persuaded me that I’ve indeed emailed the proper agency (and a pair of additional messages to Dr. Frank Raslear, the stated contact person for the accidents workbook, bounced back to me).
With silence comes ambiguity. Have my queries been remanded to some inert, serpentine queue, or have they rather cowed the Association’s best and brightest into a collective hush?
My self-flattery is not becoming. Either way, and after the battery of amendatory spreadsheet moves I recommended in the last post, we’re left with a data set of 50,000-plus worth of records that are, and aren’t, completely usable. They are, because the data qua data are fit for pivot tabling purposes and the like; and they aren’t because we – or I – remain unsure about their validity and meaning.
But let us suspend disbelief in the interests of proceeding apace, and assume – at least for now – that the data do remember the work hours as they truly unfolded (e.g. we’ll assume someone actually plied that 23 1/2 –hour shift clocked in there). You’ll recall that I had called for a pasting of all the data into a single sheet, and then supplementing the set with a new field that figured work shift duration (and we can call it Shift Duration). I remain bothered about the apparent 2003 vintage of the records, but again, that’s what they’re telling us.
In any case, it occurred to me that we might first want to construct a pivot table that would simply count and differentiate accident reports by Accident Type – that is, return the number of records citing non-human and human factors:
Row Labels: Accident Type
Values: Accident Type (Count)
But guess what – when I initiated the standard pivot table routine a decidedly non-routine message jutted its jaw in my path:

I don’t recall having seen that alert before, but look behind the message to the Create Pivot Table window and note the dimming of the typically-defaulted New Worksheet radio button. Then return to the Review ribbon and view what I had failed to see during last week’s post: the illuminated Protect Workbook button. (It should be added here that the FRA’s instruction to unprotect the sheets – an effort that bore fruit last week – asks the user to “click on “Tools” from the top of your screen, then select “Protection” and click on “Unprotect”, all of which sound like a Excel 2003-specific command sequence. Perhaps the data really are that old.) Protect Workbook – a preventive step I’d allow that few users actually take – seals off spreadsheets in ways that are wholly incomparable to the work performed by Protect Sheet. That latter command bats away attempts to enter data (among other things); Protect Workbook stymies what it calls structural changes to the entire file, e.g., the introduction of a new worksheet – and that’s why New Worksheet is grayed out; there’s no new worksheet to be had. And that’s the faulty destination reference (and as you see in the above shot Protect Workbook also resists pivot table construction on an existing sheet).
And while under default circumstances one can simply turn Protect Workbook on and off successively with alternating mouse clicks as per last week’s turn-off of Protect Sheet, the protection here is password-controlled:
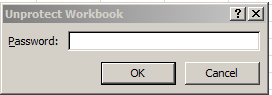
And I can’t find the password, nor do I see an allusion to it in the FRA page. If I’m missing something you know where to reach me.
But not to worry. We can simply select the entire data set, paste it to a new, blank workbook, and do our thing as if nothing had happened. I just can’t explain why this bump in the road decided to bump.
But obstacles aside, once we get there that pivot table looks like this:

Shift the numbers into Show Values As > % of Column Total and Human Factors account for 26.98% of the reported accidents, an appreciable but smallish fraction of the whole.
Of course, the data’s ellipticality – that is, the relative dearth on FRA’s page of explanatory deep background on the data – throws a caution at any accounting of what the numbers really tell us, but this is what we have.
We could then pursue the surmise that human-factored accidents associate themselves with work shifts starting at the extremities of the day, that is very early or very late, and perhaps in different distributions from the non-human incidents . We could try something like this:
Row Labels: OnDutyTime
Column Labels: Accident Type
Labels: Count of OnDutyTime (again, as % of Column total. And because we’re compiling percentages that necessarily add to 100% we don’t need Grand Totals):

Recall that those are 50,000 cases tossed into the table, no small universe. Note the human factor percentage for shifts beginning at 6AM, which in absolute numeric terms comes to 1093 accidents. Of course, these data require a definitive set of denominators before salient disproportions in occurrence can be proclaimed; that is, we need to know the actual numbers of workers reporting to their job, and when. After all, 6AM may simply be the start time that predominates.
And while we’re continuing to wonder about data quality, I’ve only lately come about across a record – in row 1300 to be exact, in the pre-merged Quarter 4 sheet. It archives a worker who commenced his/her day at 7:01AM on October 19, and punched-out at 1:01AM – on October 21, exactly 42 hours later. The accident on that shift befell the worker at 3:30AM on the 20th, the only day in the span that could have contained a 3:30AM. Among other things, it would appear that, accident notwithstanding, the worker remained on the job for another 21 or so hours. But you’ll have to ask the union about that one.
But I’m still waiting for an answer from the FRA to my questions. I’ve emailed them, after all – and that means they know where to reach me, too.

Leave a comment