Faced with the choice between counting trees or humans I’d professionally recommend that you opt for the former. Humans, after all, are mobile and moody; they’ve been known to spurn or even flee from the ones doing the counting, or slam the door in counters’ faces, or lie to their honorably-intended questions.
Trees, on the other hand, have nothing to hide, and couldn’t hide even if they did. A wondrously compliant and agreeable life form, those trees; and the Paris’ factotums charged with counting them have put together a census of their findings in the Open Data Paris site here. (Tip: click the Export button in order to start up the download, and follow on with a click on the Télécharger en Excel link.)
Now if you think you’ve heard the tree theme before in this space you’d be right; we’ve already foraged through the count of New York’s trees in our December 14 post of last year; and after having refreshed my own recollection I see that the Apple’s dataset, at least as of that writing, comprised 623,000 or so entries, give or take a sapling. We see that the Paris itemization, on the other hand, returns 104,000 trees, a perfectly plausible proportion in view of the fact that the city’s square-mile area measures about one-seventh of New York’s. At the same time, however, I can’t say if the data are comprehensive, or presume to be.
In any case, a first look at the data exposes an Open Data Paris commonplace: a spreadsheet-wide application of the Wrap Text option and its nettling consequent, an obscuring of much of the text in a whole lot of the sheet’s cells. I’d thus hasten to click through a global Wrap Text turn-off, and an ensuing standard but necessary column auto-fit.
And about the numbers themselves: I don’t know about yours, but my download aggrandizes the Circonference (tree circumference) and Hauter (height) values with a comma – the French representation of a decimal point – and a meaningless trailing zero, neither of which appear in the data as framed on the Open Data site:
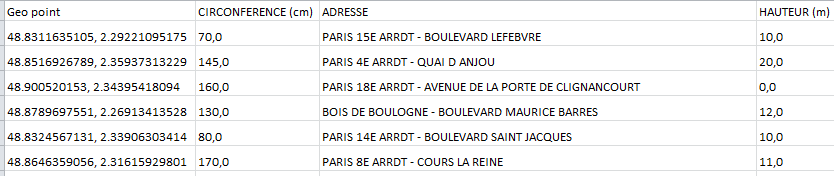
I suspect these elements are implicit in the web data and as such are being suppressed by some preemptive formatting scheme, but explanations aside I for one don’t need them, in part because my obstinate American regional settings can’t compute the comma, and so casts all the numbers into fallback text mode.
The way out, aside from handing my regionals over into French hands: do a find and replace on columns B and D, in which a find for ,0 is to be replaced by nothing. That works – kind of – because while my version indeed restores the entries to their honorable numeric standing the find and replace also somehow performs a hyper-substitution, in which the comma has been made to give way to a decimal point and three zeros for which I haven’t asked. Ok – the zeros will respond to three decrease-decimal clicks, but I don’t quite know why they showed up to begin with.
And the Date Plantation (planting) numbers in G are no less curious. First, of course, there are all those 1 janvier 1700 entries that the download rewrites into 1700-01-01 text form, text in part because Excel can’t deal with a date preceding January 1 1900. But either way I suspect 1 janvier 1700 stands as a placeholder for a tree sans birth certificate. The other dates, however, have remarkably rewritten themselves, guarding their true quantitative character – or at least they’ve done so on my system, e.g., 19 avril 1998 to 4/19/1998, even negotiating my American regional month-first syntax with panache. But those 1700s – of which more than 68,000 are sprouting among the records – are a formidable cluster, and will stand in the way of your attempts to group the data by date.
But the tweaks keep coming. It seems to me that, among other objectives, a simple breakout of tree totals by arrondissement (or district, of which there are 20 in Paris) would be of service, but the Adresse data in which the arrondissements are sealed aren’t yet up to the task (as per the above screen shot).
The pivot tabler would want record 1, for example, to release its 15 alone to the analysis, with the item shedding its redundant Paris and Arrdt identifiers and address. To get there, I’d first conduct a Z to A sort on the Adresse field, because around 10,000 of the tree records bear the provenance of either the Bois de Boulogne or Bois de Vincennes, large parks flanking Paris’ western and eastern edges, respectively. These carry no arrondissement information; and so the sort jams these to the bottom of the data set, from which they can (at least temporarily) be parted from the other, usable records via the faithful blank row.
Next I’d open a new column to the right of Adresse, call it Arrond or some such, and immediately format this upstart field in General terms – because Arron has inherited the text format of the neighboring Adresse field, and left to those default devices will deactivate your formulas into impressive but useless inscriptions.
And here’s my formula, entered in what is now D2:
=VALUE(MID(C2,FIND(” “,C2)+1,FIND(“E”,C2)-FIND(” “,C2)-1))
Remember that we’re looking to extract the arrondissement numbers peppering the Adresses in C, a search issuing a call for the MID function’s search-and-pluck routine. Here MID identifies its operational starting point by finding the position of every entry’s (first) space – invariably 6 here, by the way – and adding 1, because the arrondissement number itself need start at the next position, 7. It then figures the length of the MID character extraction by subtracting the position number of the ” ” from that of the E that invariably shadows the right end of the arrondissement number, and subtracting 1 in turn – because both the space and the E sit outside the arrondissement number and would thus overstate the extraction total by 1. (The E abbreviates a French numbering prefix, by the way, the equivalents of “st” or “th”. Thus onzième means 11th, deuxième 2nd, and so on. And the ER that attaches to the 1st arrondissement stands for première.) If you’re happy with all that, copy the formula down D.
And why the VALUE? Because absent that revisionist touch, the results would assume text form, by itself not dire; we’re not interested in adding arrondissements, after all. But reel text-formatted arrondissements into the Row Labels area of a pivot table and they’ll sort like this:
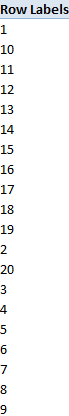
That’s how text/numerics sort, regarding each of their columns distinctly, and sorting these left to right.
Now we have to figure out what we can learn from all this.

Leave a comment