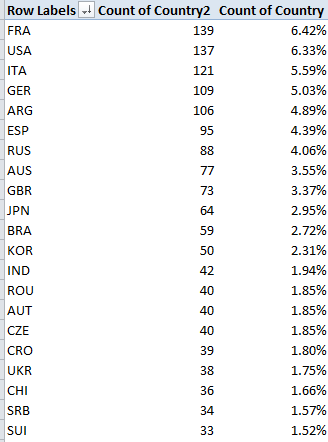
Now that we’ve established the fact of the relative French hegemony over the men’s rankings a breakout of said parameter would appear to be in order, that is, something like this:
Row Labels: Rank (Grouped in bins of 100; needless to say you can demarcate these as you wish)
Values: Rank (Count)
Slicer (or Report Filter): Country
Slicing for France I get:

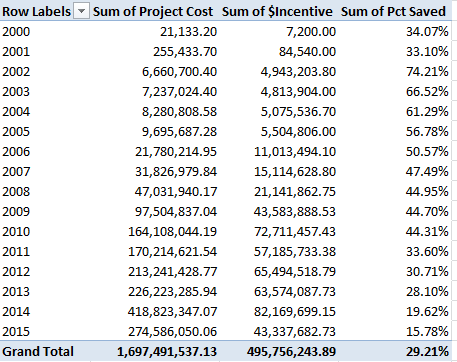
It must be the wine. With 40 players in the top 400 – and the US has 30, by way of comparison – France is doing something right, and by turning the values over into Show Values As > Running Total mode (Rank serves as the Base Field) you’ll see

That is, the top-ranked half reaching through 1100 counts 96 Frenchmen, or 69% of their total, a favorably top-heavy distribution. The equivalent US proportion stands at 53%.
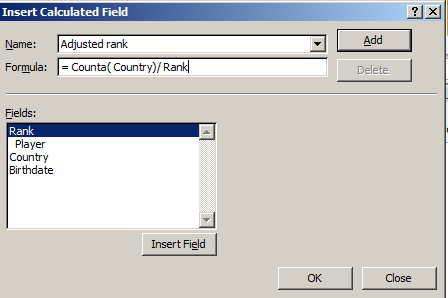
Now of course there’s another variable we’ve neglected till now – Age, which should have some notable things to say about who’s ranked where. First, I’d calculate age by posting the TODAY() function in some unoccupied cell, say L1, and range-name it, with all due sparseness, t. Then name E1 Age and enter, in E2, =(t-d2)/365.25.
That expression, which we’ve seen before, subtracts the player’s birthdate – a number, after all, when all the formatting is said and done – from today’s date, whenever that day may fall, and divides the difference by 365.25, or the near-average length of a year.
But note that 17 players report no birthdate, and so by sorting the ages Oldest to Newest we’ll drop those empty readings to the bottom of the dataset, wherein we can ask our perennial blank row to shove the vacancies from the date-bearing records.
Rounding the results to two decimals, we can begin by pivot-tabling a breakout of average age by grouped rankings, here with the presently usable range (through row 2150) e.g.:
Row Labels: Rank (again, Grouped by 100)
Values: Age (Average). I get

And that, I would contend, is interesting. Top 100 rankers are the oldest, their 28.79 years exceeding by 1.6 years the penultimate average of 27.19, which happens figure in the very next tranche of 101-200. Indeed, that 28.79 betters the overall men’s average by 4.74 years, not a trifling disparity, and doubtless a meaningful one.
Next, a simple frequency distribution of ages across the rankings would be correlatively valuable, but it isn’t that simple. Start here:
Row Labels: Age
Values: Age (Count)
It’s when we try to group the ages – and I want to organize them in units of one year – that the problems fly off our racket:

Now we ran into the extended-decimal problem some time ago, having alleviated that unsightly tableau courtesy of a consultation with Debra Dalgleish (sorry for misspelling your name last week, Debra). All we need do is delete the number’s decimal portion

and proceed, or so we’d like to think. But when we click OK we see

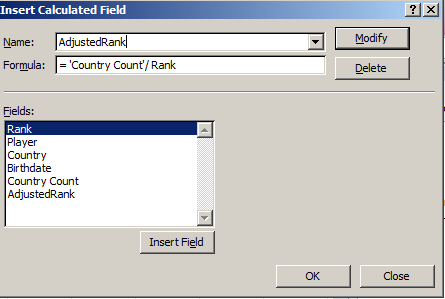
That is, the “By 1” entry in the above dialog box is all-too literal, squeezing the ages into tufts of two years, describing an interval of one year. But I want each year stand-alone, and decoupled from any companion age. And that is a perfectly standard stratagem, one in fact that could be engineered quite swimmingly without any grouping at all under “normal” circumstances – that is, were the data-set ages decimal-free at the outset. But because our field’s ages are now precise to a fault, we need to rewrite E2 thusly:
=ROUND((t-D2)/365.25,0))
thereby flattening Novak Djokovic’s 28.18 years into an uncomplicated, but real 28.00 (i.e., that is a meaningful 28, not a format-tinctured 28.18). Copy down the column, and refresh the table. Now I get (ages sorted youngest to oldest):
Flip the numbers over into % of Column Total and throw in Rank (Average, two decimals) in Values and

21 is the modal age, but with an average ranking of 1265.73 that cohort has yet to hit its stride. Note 28’s 719.32, but check out the even lower rankings for 30 and 31, numbering 68 and 40 players respectively. And the 34 34s score even better.
You may also be intrigued by the one 48-year-old urging himself upon the rankings, instated at 1716. That demographic belongs to the Israeli/American Oren Montevassel, who as of this writing sits at 1727 (remember our data take us back to December of last year). His Twitter account states its owner is “…considered best player in the world for 40+”, and that judgment may be wholly justified.
In fact, 125 players shared the 1716 ranking, presumably because it amounts to just a few tournament rating points. And to that stratum also belongs the rankings’ youngest entrant, the Italian Nicolas Merzetti, who with a birth certificate (it’s been translated for me) dated October 29, 1999 is less than a third of Montevassel’s age.
Hey ATP – where’s your publicity department? Why aren’t these two guys paired in a doubles team?