Among its definitional essentials, of course, is the idea that terrorism is aimed at someone, and/or on occasions somethings; and the Global Terrorism Database’s densely-fielded and sub-fielded data set has a great deal to report on the terrorist toll.
In the interests of first exposition consider three superordinate fields: the 22-category Target Type, (targtype1_txt, column AJ), Number Killed (nkill, CW), and Number Wounded (nwound, CZ), all of whose particulars are itemized in the GTD coding book available for download.
Again, the permutations are plenteous, and so only a few can be proposed here. We could start with a breakout of target types by five-year groupings (once again note the absent 1993 data):
Rows: targtype1_txt
Columns: iyear
Values: targtype1_txt (by % of Column Total) Click PivotTable Tools > Grand Totals > On for Rows Only. The column totals must of necessarily yield 100%; as such we don’t need them.
I get:

(Remember again that the percentages read downwards.)
I was struck by the decline in Private Citizens and Property targets, that cohort’s percentage having peaked in the 2005-2009 tranche, following a steeply-sloped ascending curve. Note as well the downturn in what the GTD calls Business targets, a likely pointer to Vietnam-era sorties against corporate sites, and the severe fluctuations in Military targets across the 1970-1984 span call for some considered drill-downs into country and/or region. Again, we need to recall that the percentages record intra-tranche distributions; in absolute-numeric terms, the 2010-15 interval (and yes, it’s six years) was by far the most terror-ridden.
Apropos the above conjecture, if we confine the target data to the United States by electing a Slicer (for country_txt) and ticking that country, I get:

My guess about Business needs to be rephrased, in view of the leap in such targets in the 2000-2004 tranche. But if we turn off the % of Column Total enhancement (by replacing that selection with No Calculation) and restore the table’s absolute numbers I get:
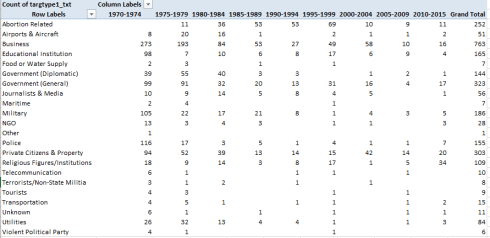
We see here that the pullback in actual event counts across the tranches complicates the analysis. 273 business targets incurred a terrorist act in the 1970-1974, nearly five times the 58 between 2004-2009.
But of course the human toll of terrorism transcends the target counts, and the GTD brings those numbers to light. We could begin by viewing fatality totals by region and tranche:
Rows: region_txt
Columns: iyear
Values: nkill
I get:

The monumental spikes in terrorist-inflicted deaths in the Middle East, South Asia, and Sub-Saharan Africa are declared with chilling clarity, along with the striking recession in victims in Western Europe. The aberrant total for North America in the 2000-2004 tranche is a consequence of 9/11, of course.
We could then look at fatalities by country and tranche. Reintroduce country_txt to a Slicer, and in the interests of presentability transport the grouped year data into rows. Summarize the nkill values by average (rounded to two decimals), and bring back nkill into values again, this time by sum. Click Slicer for United States, for example, and I get:
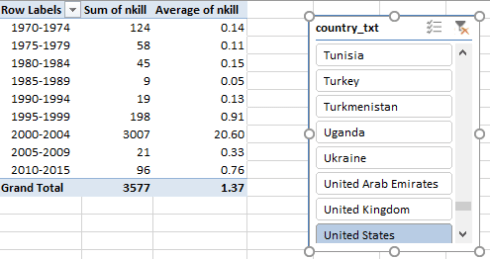
Thus even as US led the world in incidents from 1970-1974 with 931, those attacks were predominantly non-lethal. Again the tragically high total and average for 2000-2004 are explained by 9/11.
The data for the United Kingdom:

Apart from the 9/11 cataclysm (which ultimately can’t be ignored, of course), average attacks in UK, particularly in the earlier tranches, were substantially more deadly than those in the United States.
For Iraq:
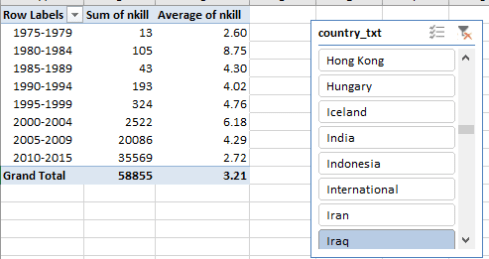
The enormous lethality of the country’s terrorist carnage, both in absolute and average terms, is unambiguous, though the drop in the per-incident average for the latest tranche is notable and probably worth investigative scrutiny. Needless to say, clicking through a series of countries should be both sobering and instructive, and can alert us to the wealth of information the GTD has garnered on the terrorist phenomenon, including a multitude of parameters we haven’t explored here – but it’s all there. There’s obviously much to learn here.
Now for a not-terribly-well-known spreadsheet advisory that could, given the formidable size of the GTD data source, greatly slim its file size and perhaps accelerate its processing speeds (and no, I didn’t always know this tip either). When a user inaugurates a pivot table, a hidden copy of its data source, called a cache, installs itself out of view; and it is the cache that the tables query, not the native source that appears before us as a matter of course in the workbook. And that means that the user can actually delete the data source, but continue to query and pivot table its clandestine twin.
I know; the prospect of querying an invisible data set sounds slightly fearsome, but if you’ve been pivot tabling that’s exactly what you’ve been doing along anyway. And by deleting the up-front data source, the one you actually see, you may thus end up halving the size of the workbook – and with a data set as imposing as the GTD the savings can be measurable.
There are of course a few downsides to the practice. For one thing, if the data set is active – that is, if your intention is to continue to add records to its complement – you’ll obviously need the data on hand, and you’ll likewise want them in place if you simply want to inspect them. And if you need to cell-reference the data in formulas – as we did last week with the FREQUENCY alternative – I know of no way you can make that happen without the data set out there, duly committed to a standard worksheet tab.
And that also means that, if you have in fact deleted the original data and want them back, you can double-click the Grand Totals cell on any pivot table. Boom – the data return, in an Excel table, no less.
And that sure beats getting them back by closing the workbook without saving it, right?

Leave a comment