In the interests of enhancing my medal prospects, I’m lobbying hard to have freestyle array formula writing approved as an Olympic sport. Preposterous and self-serving, you say? Well you’re surely correct on the second count, but a scan across the events that have, at one time or another, qualified for Olympic standing – all remembered for you on the Olympic athlete data set shelved on the Kaggle web site (sign up for free) – will reestablish my credibility. The set unfurls 270,000 entry records throughout its 21 MB of athletes who’ve mined for the gold and other precious metals and the events in which they hoped to find them, and those events make for a motely collection indeed.
Who’s in training nowadays for the Art Competitions Mixed Literature event, for example? Well, no one, in actuality, as the competitions for the best sport-themed literary submissions were last conducted in 1948, the year when all four of art events categories – art, architecture, music, and literature – were finally edited out of the Olympics. But the Kaggle data set also records all the events of which you’ve heard, too, and its medley of columns provide for a host of interesting findings.
Start with a primordial consideration: the relation of Olympic events to their competitors’ average age and gender. Here a methodological caution need be sounded. Because athletes very often compete in different events and different Olympics, a coarsened look at average ages will of course come to admit the same athletes many times. While it would be possible, on the one hand, to account for athletes uniquely via a Remove Duplicates routine, that recourse would leave the data set with one record per athlete – and only one of his/her ages, a reduction a sight too far. It seems to me, rather, that a plural counting of the athletes – each instance of which nevertheless uniquely permutes each entry per age and event – would work here.
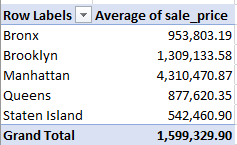
That’s my take anyway, but you’re welcome to download the data and subject them to your own assumptions. In any case, I’d start the analysis with this pivot table:
Rows: Sport
Columns: Sex
Values: Age (average, formatted to two decimals)
(Note that Sport is the superordinate rubric beneath which particular events are then subsumed. Thus the sport Swimming spreads its umbrella above 55 different events, for example.)
I get, in excerpt:

Yes, Aeronautics was an Olympic sport – once, in 1936, including a gliding event, though apparently only men took part (I don’t know, however, if the sport was gender-specific). There’s lots of sporting exotica in there (Basque Pelot – an assortment of raquet sports – was featured as a demonstration sport in 1924, 1968, and 1992 but had bona fide standing in the 1900 Games), but a close look evinces a very general age parity across genders, if not sports. We do see, and for what it’s worth, that men competitors in sailing and shooting are significantly the older (and the numbers are pretty sizable here, if you retool the averages into counts); and it’s probably noteworthy that the men are nearly two years older than women in the very global Swimming sport, in which the men-women participant numbers stand at 13,345 and 9,850 respectively.
And what about average age by gender by Olympic year, and gender distributions (keep in mind that until 1992 the Winter and Summer games were conducted in the same year)? Substitute Year for Sport and I get in excerpt:

The strikingly higher averages for the 1932 games need to be explored; Wikipedia points out the economic privations wrought by the Depression pared the 1928 athlete complement by a half four years later. It nevertheless remains to be understood why those who did make their way to Los Angeles, where the games were contested, were the older ones. Perhaps they had to pay their own way, and could better afford the trip.
An additional curiosity is the age trough bottoming for women in the 1972 games (again, the numbers above reflect both Games that year). The screen shot clips these data, but in fact their average age of 25.57 for the 2016 (Summer) games pushes nearly five years higher than that for the Games 44 years earlier. Explanations, anyone? And you’ll note the far flatter arc for mens’ ages across the same span.
In connection with the above, you can also drill down the numbers by Season, the heading beneath which the Summer and Winter games are distinguished. Slide Season under Year and you’ll see, in part:

Again, a close look is called for here. The pronounced Summer/Winter women’s disparity in the selfsame 1932 competitions may be reconcilable in part by the grand total of 22 female participants in the latter Games, a figure not likely to gladden a statistician’s heart. Yet the impressive men’s Summer margin for that year of more than eight years is founded upon a more workable base of 2,622 and 330 athletes, the latter count compiled for the Winter Games. As for the watershed 1972, the women’s Summer-Winter averages come to 20.53 and 21.79. And if you’re interested in the overall, undifferentiated aggregate gender-age averages, they look like this: Women-23.73, Men-25.56. Of course, those computations have controlled for nothing (e.g. event category), so to speak, but probably mean something just the same. And the total number of entries by gender (remembering that these gather many instances of the same athlete): Women -74,522, Men-196,594.
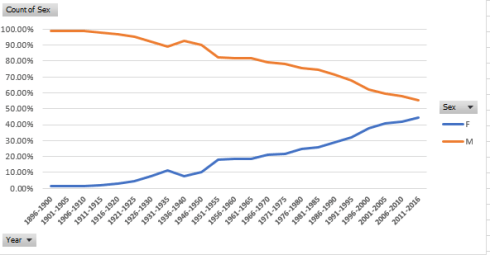
Nevertheless, those numbers should and could be associated with the years of the competition. The obvious intimation here is that womens’ rates of Olympic involvement could have been expected to rise. Thus, we could proceed:
Row: Year (grouped in tranches of five years)
Columns: Sex
Values: Sex (% of Row Total; turn off Grand Totals, which must invariably yield 100%).
I get:

Not particularly shocking, but a detailed confirmation of the “obvious” can’t hurt just the same. The proportion of female Olympic athletes has about doubled in the past 40 years, a development heavily abetted by the expansion of events open to women; committed to primitive chart mode, the gender curves look like this:
And now I need to get back to that letter I’m sending to Nike, the one requesting sponsorship for my array-formula training. Look – it’s either that or crowdfunding.