You’re wondering what to do with that discretionary $2,000,000 you have laying around – you know, that sheaf of bills that’s been angling your pillow up to untenable heights. In the interests of a good night’s sleep, then, how about dropping those two big ones on some New York real estate?
It sounds like a prudent bet; even the president of the United States has been known to commit some rocks to the idea, after all, and if that example doesn’t inspire you you may find yourself on the wrong end of an all-caps tweet from you-know-who. So now that you’re properly inspired and keen to know what you can get for your seven digits, you’ll want to consult the data set of the New York’s property sales for the year Feb 1, 2017 through January 31, 2018 – 60295 of them, or 165 a day – brought to you by the folks at Enigma public data, who’ve joined the sales records from a pair of City agencies. You can download the set over there, once you’ve signed into their site (for free).
Shift the default Save As format from CSV over to standard Excel and you’ll wind up with a 13 MB workbook – not a prohibitively weighty file, but with 62 fields that pull all the way into column BJ you may find yourself grabbing onto the scroll bar with prohibitive pique. You may thus want to abolish fields not likely to serve your analysis, starting with borough_code in Column A; you’d doubtless prefer to work instead with the five actual borough names filed in the curiously named borough_code_definition field in B. Other candidates for excision, at least in my view and at least for starters: community_district_definition in column Z, school_district_defintion, and city_council_district_definition. All three in effect reiterate the New York neighborhood names promulgated in the neighborhood field in what was, at least at the outset, housed in column B. Those curtailments kick back a megabyte to my hard drive, and every million counts, after all.
We can next move on to some standard, obvious need-to-knows, e.g, the number of properties sold in each of the city’s boroughs, understanding at the same time that obvious questions don’t always yield obvious answers. We could try this:
Rows: borough_code_definition
Values: borough_code_definition
I get:

You may be surprised by the smallish sales total for Manhattan, as I was. But the boroughs feature different kinds of properties in different proportions. Drag borough_code_definition into Columns and substitute building_class_category_code_definition in Rows, and you’ll get the picture, which looks something like this in excerpt:

Observe the One Family Dwellings entries, and their deeply understated Manhattan representation. While these standard residential homes contribute few jags to the island’s storied skyline they loom rather larger among the byways of New York’s more suburban boroughs.
But what about property values? We could plausibly guess that Manhattan sales will lift themselves atop the listings, even as a thorough appraisal would control for building class, but for a preliminary assay:
Rows: borough_code_definition
Values: sale_price (average, formatted to two decimals with the comma)
That yields:
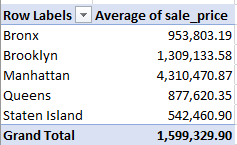
Our guess is ratified, and unsurprisingly. Now augment the Values area with these two fields, both formatted as above: gross_square_feet and floors_number_of:

Manhattan properties are clearly larger – and higher (note, however, the blanks in the floor field). A 19-floor apartment can have a penthouse; the top one in a three-floored one is called the third floor.
But it next occurred to me that those averages may have absorbed multiple apartment purchases in the same properties, a possibility that could skew the numbers – provided one is concerned to isolate unique parcels.
With that thought in mind I ran a Remove Duplicates at the data, identifying address and zip code as sources of potential redundancy (zip code, in the event properties in two different boroughs had the same address, a possibility). 12251 records were thus uprooted, after which I reran the above pivot table. This time I got:

I was startled by the Manhattan decrement, so much so that I initiated the table twice for verification. Sort the floor numbers largest to smallest in the original data set, however, and you’ll indeed discover repeated sales in the same, very tall properties. Note as well the heightened average sale price for the borough, a figure that needs to be considered carefully; after all, if a single property enjoyed multiple sales at conceivably various price points, only one of them remains here.
And since the data span precisely twelve months, a look at sales by month might prove instructive (I’m back in the original, full dataset here). But here, again, we’ve run across – or afoul – of an Engima protocol, the decision to portray dates, the ones stored in the sale_date field, in textual terms, e.g.
2017-02-01T00:00:00
In fact, because all the dates possess equal character length, a formula such as =VALUE(LEFT(W2,10)) could be put to the task, refashioning the entries into authentic values that could then be formatted in date terms. But a slightly swifter if less elegant workaround might be the thing to do here: since each entry in sale_date bears the suffix T00:00:00 (for whatever reason), selecting the sale_date column and targeting the data with a Replace All Find and Replace routine, e.g.

And that restores quantitative standing to the field’s labels. Subtract T00:00:00 from 2017-02-01T00:00:00, and you’re left with 2017-02-01, a usable date. And it seems to work all 60,295 times.
And once that deed is done, try this:
Rows: sale_date (grouped by Month)
Values: sale_date (count).
sale_date (again, count > % of Column Total)
(Note that January data emanate from 2018.)
I get:

Note the conspicuous shortfall of sales in January, which again, is the most recent of the months. Apart from that discrepancy I’m not sure if a pattern could be properly declared, though the tycoons among you may have something to say on that count.
Now to take the analysis slightly off-piste, what about the average antiquity of the properties sold, that is, years of construction? The information is there, courtesy of the year_built field. Here’s one look at the question:
Rows: borough_code_definition
Values: year_built (average, to two decimals, sans comma)
I get:

Note the relative recency of the Manhattan structures, befitting the borough’s protean impulses. Yet the collective provenance of Staten Island builds are far newer, a likely signifier of its relatively late-in-coming appeal as a residential habitat. By extension, the notably older properties of the Bronx appear to reflect that area’s comparative loss of appeal – but being New York, watch that space.
But bear in mind that the year_built data calls for a measure of review. Sort the field Lowest to Highest, and the commercial garages on 7th Avenue in Manhattan’s Chelsea district rise to the top. If in fact the facilities were completed in the reported year 1111 – about 800 years before the advent of the car – we need to commend the owners for their foresight.
Also clearly wrong is the attribution for the property in sort position 2 – the two-story home hammered together at 509 Seguine Avenue in Staten Island. Its 1680 time stamp should qualify it for landmark status, but a couple of web sites let us know that the building in fact became available in 1920.
In addition, some pause should be given to the 28 sales of properties dated 1800, most of these ascribed to a batch of condos on offer at 365 Bridge Street in Brooklyn Heights – an elevator building. In fact, it seems it was built in 1929.
And I thought the elevators were autographed by Mr. Otis himself.

Leave a comment