It’s called a teaser in the business, though my nail-biter of an allusion in last week’s post to a conceptual problem with the pivot table sourced by the Paris movie-shot data isn’t the stuff of big-time buzz and box office frenzy. But the show must go on, to wit:
We wrapped up last week’s post by counting and grouping Paris film scene shots by their arrondissements, after which I dropped some dark hint about a conceptual problem spooking the data crunched in the pivot table that was doing the counting and grouping. Now the problem can be told: My interest in these data – an interest in which you may or may not want a share – is to build a census of film locations at which any given movie unpacked its cameras, counting each such intersection of film and location once each. And what that means is this: if 20 films prevailed upon the Eiffel Tower to sit still for a shot or two, I want that activity to total 20 – and nothing more. The problem with our data is that if film A shot the Tower (or Tour, to the natives) on June 16, for example, and then returned for another take on June 28, our worksheet will have recorded each visit, thus inflating the overall sum to 21. Speaking merely for myself again, I’m looking in effect for the number of movies that trained their lenses on a particular site – and not the number of individual times a given movie adopted that site. I’d then want to gather all these data under their respective arrondissements; and again, the pivot table with which we capped last week’s post counts a site each and every time it was filmed, thus including multiple shoots by the same film.
In order to get what I what, then, I – or we- need to nit-pick the data for their redundant film/site entries, and that’s a job for the Remove Duplicates feature, which premiered here in the July 4, 2013, post (also Paris-themed, as it turns out. Check it out for the necessary Remove Duplicate steps). But the first thing you want to do, before obliterating all those excess records, is make a copy of the original data and paste it somewhere – because by the very nature of the deed we’re looking to disabuse the data of its duplicates (as we want to define them), leaving us with a leaner set of records – even as we reserve the right to work with the primordial data set, redundancies and all.
In any case, once you’ve reacquainted yourself with Remove Duplicates, click Unselect All and tick back on Titre (movie title) and addresse_complete, thus priming the search-and-destroy mission for all those records notating the same film and the same site more than once, but conserving one representative of each, of course.
And once you’ve rid the data of those 1300 or so unwanted doubles you can retry that pivot table, complete with a sort:
Row Labels: Arrondissment
Values: Count of Arrondissment
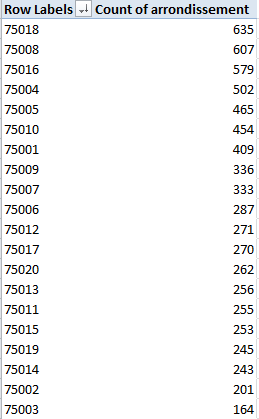
This time I get, in excerpt:
(N.B.: If you’re clicking along with me your results may vary, as they say. That’s because I took some pains to edit the data in the addresse_complete field, which suffer from more than a little inconsistency. Many addresses appear by turns with and without dashes, for example, e.g.

And that’s just one; again be advised that, absent a stiff dose of quality control Excel will regard the above as separate addresses, all because of that silly little dash.)
Note the regime change in our results. Where location honors belonged last week to the 8th Arrondissment, the revised, trimmer data with which we’re working now have resituated Paris’ movie-location epicentre to the 18th, by the city’s northern edge. It depends, then, on what you’re looking for, and how.
Now for another look and a different read of sorts on arrondissement popularity, how about toting up shooting days, and breaking these out by arrondissement? That is, why not add all the durations in days of all shoots (i.e. all date_fin_evenements minus all the data’s date_debut_evenement, where “evenement” means event), and align these to the arrondissements in which these were filmed?
Once we’re happy with that question we need to recall the original, duplicate-ridden data set (I told you to make a copy), because now we want to factor in all the shoots at all the locations, including revisits to once-filmed sites (understand as well that some films may have set their tripods down at a plurality of locations on the same day, with each and all of those days to be counted).
Step one toward that end seems simple enough – make room for a new column and call it Days, within which we want to conduct a record-by-record subtraction of shoot start (debut) dates from their finish (fin), e.g.
=D2-C2+1
The +1 above will admit the day of shooting inception itself into the total; otherwise, if you subject a shoot that begins and ends on the same day to this formulation, for example:
=D2-C2
you’ll get zero; hence the necessary + 1.
But step one is in need of a step one-and-a-half, as it were, because a wayward promenade through the data took me past about 60 records in which the fin happened later than the debut, and in the standard order of things ends usually precede beginnings. There’s a programmatic way out of that this chronological snare, though (I’m assuming by the way that the fins and debuts were simply transposed); enter in the first row of your Days field
=ABS(D2-C2)+1
And copy all the way down. ABS is an agile means for shaving any plus and minus signs sprouting from a number and returning its absolute value only – in effect, the plus equivalent. Thus, for example, =ABS(3-7) and =ABS(7-3) will both settle on the value 4.
And once all the days have been absolutized, this pivot table beckons:
Row Labels: Arrondissement
Column Labels: Cadre (just for good measure)
Values: Days (Sum)
I get, in excerpt:

Interesting, n’est-ce pas? It’s the 16th Arrondissement on which the auteurs seem to have actually spent the most time filming (in days), although I can’t tell you why. Note too that the relatively banal 11th grabs the silver medal here, even as it slouches into 15th place in the first table table pictured earlier (Domaine Publics, by the way, seem to comprise venues of the park/forest/square ilk, and note their strikingly variable ratio, by arrondissement, to Exterieurs.) And on a summatory note, consider that the grand total of all film days comes to 29,030 – or nearly 80 years’ worth of day-time spent shooting Paris scenes. Formidable.
Time for one more data-quality issue, if I may. Take a look at this data excerpt:
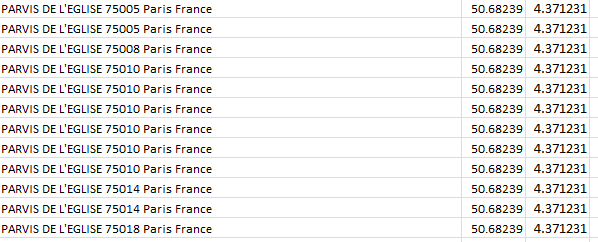
Parvis denotes a square fronting a church; but observe the assortment of postal codes above, all appearing to convene at precisely the same latitude and longitude. Moreover, those coordinates don’t even seem to be Paris-based; Google place that city here:
48.8567(latitude)
2.3508 (longitude)
And given that each degree of longitude takes in about 60 miles at this global pinpoint, it seems that at 4.371231 the data have traveled some way out of Paris – and again, according to Google, they have; the lats/longs in the above screen shot put all those churches in the Gare (station) de Braine-l’Alleud – in Belgium.
I knew there was something wrong with that sat-nav.









{kind=link}