Change may be good, but sometimes when the change substitutes apples for oranges, the surprises on the menu can be hard to digest.
Don’t worry – I won’t push that fruity metaphor much further, but when more-or-less similar datasets beg comparison to one another you do need to decide what you’re going to do with the “less”. Case in point, last year’s crime data for Washington DC, downloadable here:
http://data.dc.gov/Main_DataCatalog.aspx
If the data sound – or look – familiar, it’s because we spent some time with the 2011 DC numbers on August 12, 2012, brought back here:
You’ll note that 2011 is more-or-less similar to the 2013 rendition.
And there’s the rub, that more-or-less. Look closely at the two sheets, and, as if they’re were entwined in puzzle form, try to see what’s different about them. For one thing, 2011 matches crime incidents to their latitudes and longitudes – a useful thing to be sure, but 2013 doesn’t. And that’s for starters. With a bit of fooling around (and kudos to Excel’s Copy>Paste>Transpose feature, and the ever-perennial Sort command), your correspondent lined up the 2011 and 2013 fields respectively, conditionally formatting the 2011 names that reappear in 2013 (by dint of the MATCH function):
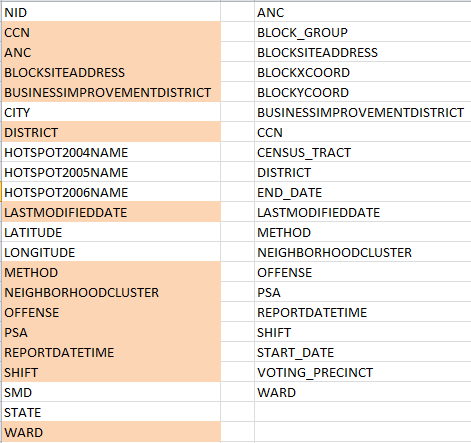
(And for a most enlightening explication of the above field names, look here.)
Apart from 2011’s larger field complement, we see as well that only 13 of its fields recur in the DC crime data two years later. Needless to say, that malocclusion could cause problems.
Maybe. Some equivocation is in order because the analyst may simply not care about at least some of those unrequited fields. I don’t think the 2011’s HOTSPOT fields will be missed, for example, and indeed, they’re nowhere to be found in 2013. And some omissions in the latter sheet are probably a good thing, in any case. 2011’s CITY field does nothing but avow the name Washington 32,000 times – a most dispensable redundancy, you’ll agree, and ditto for STATE, which iterates DC (it’s the nation’s capital and as such not quite a state, but it’s close enough) almost as monotonously, syncopated only by the occasional blank cell.
But discontinuities in the METHOD field, which does inform both sheets and presumably codes the manner and means by which reported crimes were committed, are more material. 20,000 cells in METHOD, circa 2011, were assigned an unvarnished 1 or 2, the import of which presently escapes me (again, return to this page for some clarification of these puzzlements. I’m not sure, however, that the 1 and 2 identified there comports with those numbers populating the 2011 sheet); and nowhere does METHOD in 2013 resort to these notations. There’s nothing but text in there, although to its own discredit 2013 fills more than 31,000 of its METHODS cells with the unilluminating OTHERS entry (note in addition that 2011 deploys the singular OTHER, but far less often).
And as far as these things go, then, the coding disconnect between the two years is something of a big deal. An investigator might very well want to compare crime-commission-method frequencies across years, and given the discrepant coding schemes brought to bear on the METHODS data for 2011 and 2013 that intent is hereby foiled, unless you’re prepard to mount some wholesale effort at reconciliation which might or might not be worth the bother.
Here’s another issue. Unlike the 2011 version, the 2013 REPORTDATETIME field contributes time, in addition to date, information to the parameter (time data were actually introduced in the 2012 sheet, whose data-organization maps onto 2013’s. We haven’t looked at 2012, a simple consequence of the times at which these posts have been written). That should thus enable us to pivot table crimes by hour of the day i.e.
Row Labels: Offense
Column Labels: ReportDateTime (group solely by hour)
Values: Offense

(The screen shot excerpts the whole for reasons of space and legibility.) There’s a lot to note there, among other things the swell in motor vehicle thefts in broad daylight (Theft F/Auto stands for Theft from Auto, that is, items thieved from autos).
But in addition you’ve probably noted a curiosity on your own – namely, the unvarying time-stamp of all homicides of 12:00 AM. That can’t be right, of course, and an answer to my inquiring emails to DC Data about that impossible consistency awaits.
HOWEVER – make room if you will for a revisionist epilogue, borne of a late-breaking discovery. I’m not alone, after all; the folks at DC Data have likewise made themselves well aware of the 2011-13 field incongruities expounded above, and now offer a revised edition of the 2011 data here, whose fields, time stamps, and codings line up most fittingly with their yearly successors. And that means you can copy and paste the 2011 through 2013 records onto one grand workbook and have some ringing longitudinal looks at it all. Any downsides? Well, we lose latitudes and longitudes, if you’re among the map-minded. And the 2011 homicide data are also time-stamped at 12:00 AM.

Leave a comment