In the matter of spreadsheet construction what’s worse: a man without a country, or a man with two of them? Go country-less, and your cell turns up blank; have two countries, on the other hand, and you get two records, and that’s a problem.
A problem, at least, if you’re aiming to do something simple, i.e., breaking out the Harvard/MIT MOOC student data by their country distributions.
By way of review, you may recollect that we’d copied and pasted the pivot-tabled source EdX data into a couple of new data sets all their own (see Part 1). One of these comprised nothing but Student ID and country (or userid_DI and final_cc_cname_DI as EdX’s calls them), this one been set aside because a very substantial number of those students with multiple class enrollments were, for whatever reason, identified with more than one country, e.g.,
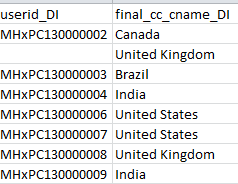
That’s because some of those with multiple course involvements show multiple international identities, either because their several IP connections reported as much, or because they volunteered them.
Those first two records in the shot above – the second of which contains nothing in the first field – stand for the same student, who’s been tracked both to Canada and the United Kingdom, a duality which could be laid to the modal IP locations pinpointed during her accesses of the two classes. And remember as well that neither country may signify a student’s country of citizenship in any event. (Her second user id isn’t there because the data have been pasted from a foundational pivot table, which by default casts duplicate field entries into its default, streamlined outline format.)
And what that means first of all that the MOOC data can nail down student locations, more or less, but can’t assert their nationalities. And it means second of all that we’re yet left with the student double-country problem, for which no elegant resolution seems to obtain. If we run a pivot table across the data in the interests of a country breakout we’ll wind up with more countries than students, as about 19,800 students seem to have been sited twice. On the other hand, my preliminary backs-and-forths with the records find that about 17,500 of these “excess” country data declare Unknown/Other for that second country, an unusable geopolitical unit in any case, leaving us in turn with about 2,300 actual nation redundancies. Because that surplus amounts to but .5% of the whole they could perhaps be triaged – that is, pulled away – from the data, and written off as something like an acceptable loss without much in the way of a sampling compromise.
Moreover, an even bulkier sheaf of records is similarly beset – the subset of single-enrollment students who report an Unknown/Other country, too. So let’s roll out the simplest, if avowedly inelegant, option – pivot tabling the data, and filtering out the blanks along with the Unknown/Others.
And for pivot table honchos like you that’s simple indeed:
Row Labels: final_cc_cname_DI (filter (blank) and Unknown/Other)
Column Labels: final_cc_cname_DI (Count, of necessity)
final_cc_cname_DI (% of Column Total)
Turn off Grand Totals, too.

Surprises? I think so. I for one am surprised by the understated American presence, less than a third of all the MOOC participants. India’s clear second ranking is noteworthy, though not incommensurate with that country’s size and economic efflorescence. From there on the distributions shrink, disperse, and smooth, apart perhaps from the 7.07% contributed by what’s called Other Europe.
Now we can return to the original EdX data and break out course enrollments by country. Here we’re not bothered by the student multi-registration issue because each course can and should be considered in its own right.
Try this table, then:
Row Labels: final_cc_cname_DI
Column Labels: course_id
Values: final_cc_cname_DI (% of Column Total)
And filter out Unknown/Other for the Row Labels
I get (in excerpt; the table is wide and deep):

That may not play very well on your screen, but try that one at home. You’ll note the interesting inter-class, inter-national variation streaming across the table, for example MIT’s two-section Circuits and Electronics representation from India – close to a third of all students there, a proportion that far outnumbers the American complement. Yet Indian contributes but 7.26% of Harvard’s Ancient Greek Hero devotees, even as the US checks in with 45.65% of the registrations. The cultural variation is nothing if not provocative.
Now glide gender into the Report Filter and click f only. Check it out – India’s women occupy 58 and 68% of all the virtual seats claimed by women in the two Circuits and Electronics classes. Turn off % of Column Total by opting for No Calculation and the absolute Indian women’s total comes to about 2700 for the classes. Click m alone in the Report Filter and the parallel Indian male aggregate for Circuits and Electronics yields about 14,000. Put another way, five times more Indian males prefer Circuits and Electronics than their female countrywomen do, but Indian women rule the cross-national female contingent.
It’s all relative then – but then, who’s to say all those Indian IP addresses were plugged into by Indians anyway?

Leave a comment