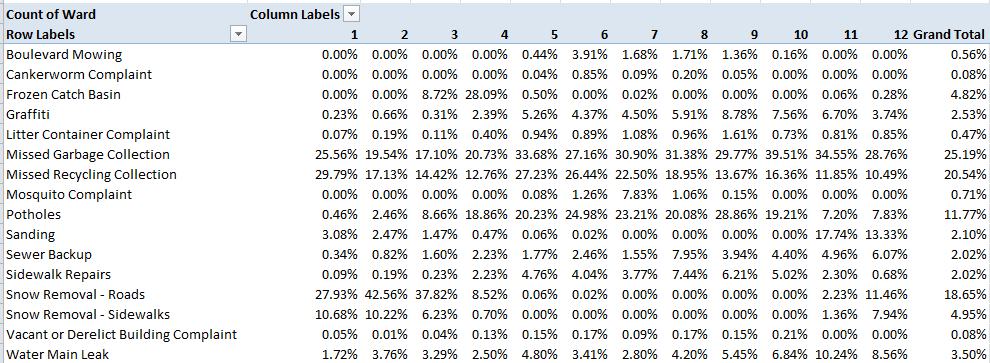
With its Gallic titular panache Les Conseillers de Paris could pass as a movie title, perhaps the sequel to the Umbrellas of Cherbourg; but alas, it’s only a spreadsheet, and the big screen on which it features is probably the one glassed inside your Samsung.
OK, so it isn’t coming to a theater near you, but the sheet has its moments, nevertheless, once you decide you want to know something about the “deliberative body responsible for the governing of Paris” and its 163 members, all of whom throw themselves at the mercies of the city’s voters every six years, including 2014.
With members apportioned from the city’s 20 arrondissements , or districts, in numbers reflective of arrondissement size (the 15th is the largest), the Paris Open Data site lists each and every serving conseiller from 1977 through 2014, and I’ve sent it your way here:
Les Conseillers de Paris 1977-2014
Once you’ve smoothed all that wrapped text curled inside the worksheet you can proceed to a couple of first general-interest findings for starters. Try this pivot table:
Row Labels: Mandature (or Term)
Values: Mandature
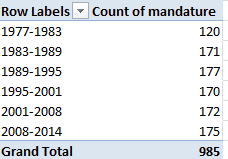
Thus we see that the 1977-1983 complement comprised only 120 conseillers, and nowhere does that defining 163 appear, even among the later mandates. The surplus figures are likely attributable to the deaths of conseillers (note the deces field in column J) and their replacements, all of whom are listed, and perhaps mid-term leavers and their successors (see the remplacement field in L). Note, on the other hand, that some deaths appear to have post-dated a conseiller’s tenure. For example, both Claude Avisse and Louis-Henri Baillot died in 2007, well after their service on the conseille had elapsed. Moreover, because conseillers who served multiple terms (e.g., Baillot) appear in the data set for each of their mandatures, dates of death appear as many times. And I can’t explain why date-of-death entries are fashioned in text format, e.g., décédée le 25 mars 1998, when they could have been made available as actual dates – particularly when dates of birth are expressed in bona fide numeric terms.
Note as well the curiously extended seven-year mandature 2001-2008,a governmental workaround “designed to avoid an overloading of the electoral calendar in 2007“, a presumable concession to the presidential and parliamentary contests of 2007.
And if you want to learn something about the Conseil’s gender representation, try this:
Row Labels: mandature
Column Labels: conseiller
Values: conseiller (Count, and % of Row Total) (and turn off Grand Totals for Rows)
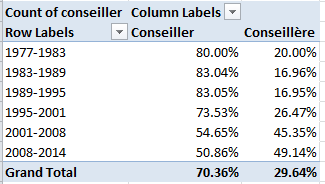
A most interesting and emphatic incline toward gender-count parity informs the table. Remember, however, that the above accords multiple counts to the same conseillers serving across multiple mandatures; if you want to break out discrete, actual conseillers by gender, then, the process gets trickier, because if you go with:
Row Labels: Nom
Row Labels: Prenom (to disambiguate conseiller’s with the same last name)
Column Labels: conseiller
Values: conseiller (Count)
You’ll pile up multiple counts for the multiple-term servers (some conseillers in fact have served in all 6 cited mandatures), and thus do little more than restate the outcomes of the screen shot right above. There are several resolutions to this pivot-table-peculiar search for unique field constituents that appear repeatedly, and here’s but one: Return to the data set, and conduct a Data > Remove Duplicates, by ticking prenom and nom as the duplicate-bearing columns. Then pivot table the 532 prevailing, definitively unique records (i.e., any and all conseillers now receive exactly one entry) again, precisely as per the instructions immediately above; and down by the Grand Totals role you’ll find 348 Conseillers – men – totalled along with the 184 Conseillères. Gender percentage breakdown: 65.4%-34.6%.
(Keep in mind of course that a removal of duplicates imposes would could be a permanent decrement in the dataset count, depending how you play it. You could of course save multiple versions of the data, pre and post-paring.)
You’ll also want to think about the dataset’s 57 fields, and wonder why the last six of them – out there in columns AZ through BE- aren’t merely entitled empty, but are empty. There’s no evident reason not to delete them, and I suspect for purely operational reasons you might well throw a good many of the other fields overboard too, as they’re only occasionally populated (and I’m still working on what their headers actually mean, truth be told. J’ai besoin a native French speaker), and the fields often have been distended to enormous column widths besides.
Still, the more self-evident data do have something to say. What if, for example, we wanted to calculate the average conseiller age of at the point of election, i.e., date of election minus date of birth? That’s a most practicable task – begin by parting the fields with a new column, say between A and B, call it Age at Election or something like it, and, in what is now B2, enter
=(J2-AT2)/365.25
That is, subtract the number of days separating a conseiller’s birthdate from the day on which he/she was elected, and divide the total by the average day-length of a year. Then head towards this pivot table:
Row Labels: mandature
Values: Age at Election (Average, round to two decimals).
I get:
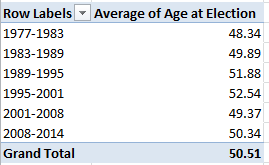
The consistency is notable, though the average age ascent – about four years, between 1977-2001 and 1995-2001 – may reflect large numbers of triumphing incumbents, all of whom of course aged about six years between elections.
Then swing conseiller into Column Values:
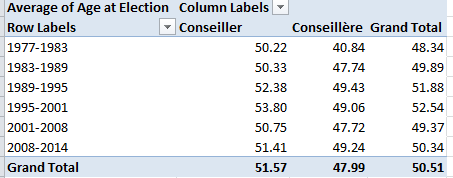
We see women members are the consistently younger, perhaps comporting with their relative, aggregated newcomer statuses.
So check it all out; vive la feuille de calcul. That’s spreadsheet to the rest of us.