David Cameron wants your vote, but he can’t have mine; neither can Ed Milliband, Nick Clegg, Nigel Farage, or Natalie Bennett, if they and you must know. I’m a legal alien, you, see, and can’t exercise the franchise here in the UK, where they tell me there’s an election May 7, and I believe them (they – and they know who they are – are perfectly happy to take my taxes, though; complaint desk, please).
Apropos all of the above, if you’ve been waiting for the Conservative Manifesto it’s here at last, minted in all its PDF, ethnically-sautéed glory, and ready to head your way from the (curiously) small Read it here link bordering the accompanying video. And in this connection the Guardian has put its abacus to the manifesto and keyword-counted the document:
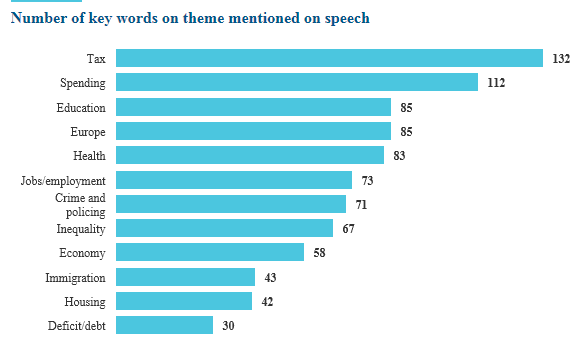
(Don’t be misled by the “mentioned on speech” title clause. The Guardian states elsewhere in its story that the counts are in fact drawn from the actual manifesto.)
Question then: could you and I do the same? Answer,: yes, or something pretty much like it. After copying and pasting the Manifesto into a spreadsheet, we might be able to throw a function or two – more particularly COUNTIF, or depending on the way in which the data break, a FIND, at the text and get an enumerative handle on the keyword counts.
And so in the interests of pre-testing I cracked upon the Manifesto and dragged, copied, and pasted a swatch of text into a sheet, looking something like this:

Surprise. Surprise, because pasted text typically narrows itself into a single column, its row/lines protruding therefrom, e.g. this copy and paste:

That shot isn’t a paragon of lucidity but trust me; all these lines and all of their text are seated in the A column; and undifferentiated data of this stripe explains the need for a Text to Columns feature, the enabler of choice for parsing the lines into smaller, meaningful fields.
But our data are nothing of the sort. The Manifesto text has already done its parsing, breaking each and every word into a cell all its own, for reasons I can’t immediately explain.
And I can’t explain this either: when I later attempted a select-copy-paste replication on the Manifesto, it hemmed itself back into a single column, as per the screen shot directly above. What had I done right/wrong the first time? Or had the Conservatives shipped a reformat while I wasn’t looking? I really don’t know, at least not yet; but I do have the unlovely word-to-a-cell version for you, and it’s here:
Mysteries aside, one might ask about the respective analytical potential inhering in the two motifs exemplified above. I would submit that the rendition before us – in which each Manifesto word owns an unshared cell address – is superior, because its discrete word segregation empowers us to make productive use of the relatively simple COUNTIF.
And for an understanding of that productivity think about how COUNTIF works, in its ultimately binary inclination. If you enter
Day after day it rained
in A10 and ask COUNTIF to look for instances of the word “day” (and let’s hold off on the syntactical issues for the moment) you’ll return 1, not the 2 for which you were hoping. COUNTIF merely tells you if the searched-for item is there at all: if it is, it’ll serve up a 1. If it isn’t, you’ll get a 0 (and not an error message, by the way).
Thus if the text data are conventionally organized, that is, if they’re massed into a single column, COUNTIF can’t accurately tell you how many times a word appears in the excerpt, telling you instead only whether or not the word appears in the line, frequency notwithstanding. But our data, for whatever reason, grant each word a cell; and so the 1 that COUNTIF can deliver will suffice (consider also that, unlike standard database features, COUNTIF can conduct cross-column/field counts).
And by way of further extended preamble let’s try and identify where in the sheet the Manifesto itself actually starts. It seems to me that the Manifesto proper inaugurates itself on row 114, and closes at 3741 (row 3742 features a personal attribution that is clearly extra-Manifesto). I thus named the range sprawling across A114:AD3741 (AD being the outermost text-bearing column) Man (and that name should accompany your download). Note as well that the copy-paste as we see it may have inflicted a measure of apparent text relocation here and there, but if we’re conducting individual word searches, that shouldn’t much matter.
In any case, if we want to count instances of the word “tax”, for example, we could repair to the out-of-range cell A3744, type tax therein, and enter, in B3744
=COUNTIF(MAN,A3744)
You should get 85; I do, at any rate. But we see above that the Guardian counts 132 occurrences of the term, a departure that one assumes could be explained at least in part if the newspaper admitted word variants – e.g. “taxes”, “taxation”, along with “taxes.” or “taxes,” etc. – into its equation. One way we could approximate toward that widened space:
=COUNTIF(MAN,A3744&”*”)
The above construction looks in effect for tax*, and so should assemble most of the kindred references to the central term (though it’ll also find and count “taxi”, and of course won’t find “levy” or “duty”. The science is inexact, though it’s still probably more science than art). And with that criterion in place, I get 146, a good deal closer to the Guardian total.
Note the syntax above calls for a string concatenation, even if the item to be counted turns out to be numeric. Thus, for example, counting every number exceeding 100 in cells A1:A100 would require
=COUNTIF(A1:A100,”>”&100)
And that string stipulation sets COUNTIF apart from the standard IF, which welds operators to its truly numeric values, e.g.
=IF(A6>100, “Pass”,”Fail”)
In any case, you can try COUNTIF in its several flavors on the other Guardian search terms, and see how your counts compare with theirs (I don’t know how the paper realized its counts, by the way). Thus I get just 19 for “housing”, even as the Guardian comes up with 42. “hous” somehow gets me 37, though, and “home” 79. Did the Guardian simply add totals for incomparably-spelled synonyms? It surely did for deficit/debt, for example, and when I combined the two I got 32 to the paper’s 30 – not bad. Again, the Guardian gets 73 for Jobs/employment; I get 70, but I’m pretty far off on Europe (31, 44 with Euro) and immigration (my count: 26). But I get an in-the-neighborhood 52 for “economy”, near the Guardian’s 58 (though “econo” yields me 109).
Again, I don’t know just how the Guardian arrived at its counts, which in some cases put considerable distance between themselves and my totals. Maybe I’ll Tweet them about their methodology.
And by the way – would it be possible to roll up keyword counts even if the data hew to the one-column regimen? It is, but you might have to make recourse to a formula looking something like this:
{=SUM(LEN(SUBSTITUTE(TRIM(A2:A100),” “,” “))-LEN(TRIM(A2:A100)))+COUNTA(A2:A100)}
And explaining that one here would blast my word count sky high.

Leave a comment