You know what they say: it isn’t the number of records, it’s the number of parameters.
But ok – you’re not buying into my bid for aphoristic glory; it was I indeed who uttered that would-be maxim, and Bartlett’s isn’t stopping the presses to find a place for my putative quotable. But it’s still true. Show me a data set rife with fields and the analytical permutations multiply; and with 25 of them, most of them carrying some investigative promise, the Connecticut traffic-stop data justify a round of deep looks, and even had they comprised a good deal fewer than 841,000 records.
But the looks won’t help if you can’t understand what the data are trying to tell you, and as intimated by last week’s post I hadn’t yet wholly apprehended what some of those Intervention field codes actually meant to say. But a post-Part 1 publication discovery brought me here, to a supplementary page on the Connecticut data site that charts much of the traffic-stop data and sheds some necessary light on the codes as well (and we may have something to say about those charts a bit later).
Thus informed, we can start taking some of those looks, starting with pivot tabling intervention or traffic stop times, e.g. a basic datum that’s gone uncharted on the Connecticut page:
Row Labels: Intervention Time (grouped by Hours)
Values: Intervention Time (count)
Intervention Time (again, here by % of Column Total; and you don’t need Grand Totals here)
I sorted Largest to Smallest by the latter parameter:
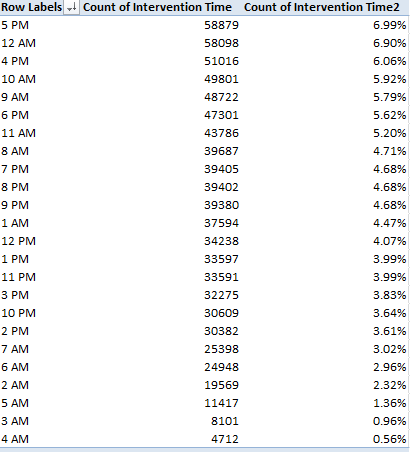
Not shockingly, the six sparest stop hours step through the 2 AM – 7 AM band, but the two busiest slots – 5 PM and 12 AM – aren’t remotely contiguous. Of course the intervening variables need be considered – the table-leading 5 PM may be nothing more than an expectable artifact of rush-hour volume, but the midnight stops may have more to do with official suspicions of drunk driving.
And that’s where you may want to kick off the parameter mixes and matches, though you’ll need to prepare yourself for some wheel spinning as your processor braces for each 841,000-record refresh.
You could, for example, crosstab stops by hour with day of the week:
Row Labels: Intervention Time
Column Labels: Day of Week
Values: Day of Week (Count, % of Row Total)
I get:

You’ll note the far-from-evenly-distributed percentages, some of which accord with common sense more fitly than others. The diurnal triumvirate of Friday, Saturday, and Sunday account for but an iota less than half of the 12AM stops, an apparent, unsurprising obeisance to traditional party nights. Indeed, the single largest day-time split -23.41% – rears its modal head in the Saturday-2AM coordinate, a day and an hour when inebriation might top the law enforcement checklist for possible stop-search justifications (of course that percent holds a relative predominance for 2AM; remember that hour falls into the 4th-lowest stop rank).
And we could go on; the tabling permutations are vast, and if you’re so inspired you’d be happy to spend a productive day breaking out this field with that, and to productive effect, I’d allow. But a return to our leitmotif – the association of race with police-stop likelihoods – might be in order. Beginning with a premise-setting table:
Row Labels: Subject Race Code
Values: Subject Race Code (Count, % of Column Total)
we’ll find that all stops of black drivers contribute 14.08% of all detentions (A means Asian, and I signifies Indian American; these clarifications issue from the above-referenced Connecticut data site link), a significant if not enormous disparity for a state whose African-American proportion stands at around 11.5% . But break out race stoppages by Reporting Officer Identification ID (I’m not sure the word Identification there isn’t redundant):
Row Labels: Reporting Officer Identification ID
Column Labels: Subject Race Code
Values: Subject Race Code (and leave Grand Totals for Rows on, at least for the moment)
And the numbers turn up notable variability in the race/stop distributions (understanding that for some officers the numbers are small). Are these a matter of localized race demographics, concerted bias, or some other confounding input? That’s your reportorial cue, honored data journalist.
And now two generic final points. First, run the Intervention Location Name data through Row Labels, and you’ll see, in part:

You know what that means – a dam-breaking spate of discrepant place spellings, overwhelmingly – but not exclusively – beset by superfluous spaces. Those missteps can be set right with the TRIM function, but other inconsistencies may call for on-the-ground rewrites. Welcome to big data, folks.
The second matter is strategic, neither novel nor cleanly resolvable, at least not here. We’ve properly noted the Connecticut page laden with charts vouchsafing themselves to the traffic-stop data. Those graphical alternatives to our pivot tables pose the old, invidious question of preference: which object makes the sharper point, for example – this:
![]()
or this?
(I should add, before you answer that question, that some Connecticut charts stake their data to some rather doubtful realizations, even by the lights of exponents of the oeuvre. This chart of stop frequency by day of the week:

Orders its bars in effect by a largest-to-smallest sort and not its native day-of-the-week sequence, a most debatable realignment for points fixed in the chronological stream; and it does the same for stops by age.)
The blandishments of the visual – a bar chart’s expression of relative magnitude through the ancient expedient of bar length – is ancient, but communicative just the same. But If that encomium means to cast its vote for charts, then we’re left with the obvious need to defend pivot tables altogether, even though that remit smacks of reductio ad absurdum, and I don’t think anyone would find in the tables an infrastructural source of those very data to be charted, and nothing more. It sounds nearly silly to ask, but when then does the analyst opt for the pivot table?
I think that interrogative calls for a long answer, but my editor just gave me the “cut” sign. But at least I got the question in.

Leave a comment