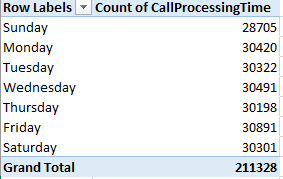
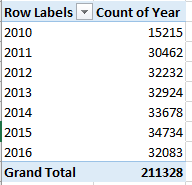
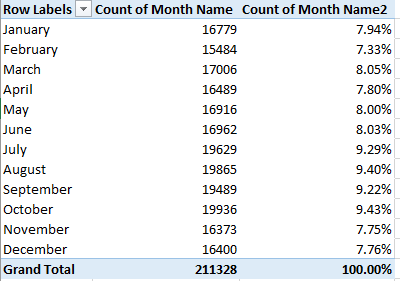
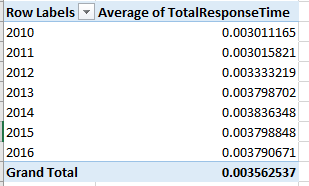
When is an election over – when the winner is declared, or after the votes have been counted? The alternatives are neither mutually exclusive nor mutually determinative; while the declared winner readies his regime change, the ballot count proceeds, eerily distanced from an outcome that has already been affirmed and conceded. Mr. Trump plunges ahead toward his office, while the shadows umbrate some other figure on the wall.
Such is election 2016. Both presidential candidates seem to have won – something – but only one gets to hold a party on January 20th, courtesy of the misshapen, superstructural interposition we call the Electoral College (note that Donald’s Trump’s popular vote percentage falls beneath that of both George W. Bush – himself a minority-vote winner, and Mitt Romney, who outpolled Trump but lost. Of course a large third and fourth vote this time has something to do with that disparity).
But the vote continues to be tallied, and a most useful, near-real time spreadsheet of the numbers as they stand right now is yours to download, this time the courtesy of David Wasserman of the Cook Political Report site. Indeed – on a couple of occasions I’ve clicked its on-site refresh button and watched the number change right then and there. To get the sheet, look here (note the sheet inhabits its space in Google Spreadsheet form, and sometimes its File command – the one you’d click in order to download the data in Excel mode – isn’t always there. It may take a couple of accesses before you see it. That’s been my experience).
Spreadsheets of this kind and organization again ask again question I’ve posed here more than once– namely, the one about the intentions you bring the data. If they’re purely self-educational – i.e. you simply want to learn what the sheet has to say about the current count – then it’s perfectly fine as is, and by definition there appears to be nothing more to do. Read, then, and be edified.
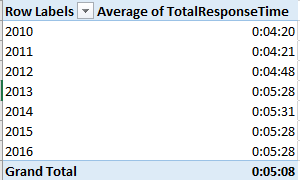
But if you want to act upon the data – that is, try your analytical hand at learning something more than what you’re seeing – you’ll need to decide if the worksheet calls for some manner of restructuring. If for example you decide you want to treat the numbers to a round of pivot tabling, than restructure you must: You must, for example, strip away blank rows 6, 10, and 25, along with the textual captions slid into 11 and 26. You’ll also need to vacate rows 7 through 9 as well; leaving them alone will unleash a triple count of the vote totals upon any pivot table, as the U.S. Total in 7 doubles the individual state vote count, and the Swing/Non-Swing State data in 8 and 9 duplicate the count yet again.
But even if one opts against the pivot table strategy there’s still work that could and perhaps should be done, and things to be learned from the sheet. First, I’d restore all the numbers in the data set to their default right alignment; centering New York’s 4,153,119 votes for Clinton (as of this writing) immediately atop North Dakota’s 93,758 imposes a false presentational symmetry for the values, and the formulas in columns E, F, and G, e.g. in E7:
=B7/(D7+B7+C7)
could have submitted to the more parsimonious
=B7/L7
OK, that one’s a small point, and here’s another: the parentheses bracketing the formulas in the I column could be lopped off. But the sheet’s color-scheming raises another, weightier issue, begging the question if the collection of tints before us embody a set of conditional formats, or rather and merely a pastiche of fixed-color design decisions. The answer is all of the above; conditional formats range across some of the data cells, while the latter motif dyes others.
To discover exactly which cells have been subjected to which treatment, we can make our way back again to the agile F5, Go to > Special > Conditional Formats option (we’ve done this before):

Ticking the option button above instructs Excel to go to, or select, all the cells in the sheet that in fact bear some conditional format, and following through here I get, in excerpt:
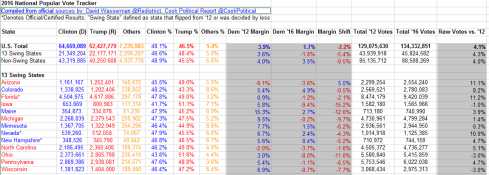
Note therefore that a good many cells – e.g. those populating the first seven columns – sport static, manually-colored hues that represent party associations – blue for the Democratic, red for Republican, yellow for the generic Others. The “margin” columns of H:J, however, were conditionally formatted, for example:

That is, the numbers in the above cells exceeding zero revert to Democratic blue, bespeaking a win for that party; the less-than-zero values turn those cells Republican red.
But note that the M column has been likewise conditionally formatted, even as none of its values seem to have undergone any change of appearance. Click any cell in M, click Conditional Formatting > Manage Rules, and you’ll understand why:
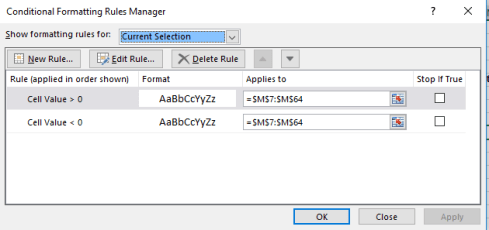
While the greater/less than zero conditions have been entered here as well, the worksheet designer neglected to assign any formatting consequences to the M cells. (Cell A2, disclosing nothing but identifying information about the sheet, has been conditionally formatted as well – but I’m assuming that treatment is a simple, inadvertent mistake.)
But consider the state-name enumerations in the A column. Their respective colors reflect a win for the appropriate party, and these could have and should have been given over to conditional formats (in this case formulas) – and they weren’t. Absent that device, the spreadsheet designer apparently needs to inspect the present vote totals for each state and manually apply the relevant color, again state-by-state. The recommended formulas look something like this (after first selecting the state names in A12:A64):

That is, if the vote in the C (Republican column) exceeds that in the associated B column, color the cell red. Let B exceed C, and the cell reverts to blue. Of course if we had reason to suspect or anticipate a state win for Others, a third condition would have to be introduced.
Now there’s another non-pivot-table-driven finding of interest that the data, in their present incarnation, grant us. Note that states whose vote count has been officially finalized are asterisked, and so we might want to tally that count in turn. In effect, then, we want to look for the appearance of an asterisk in any given state’s name, a task amenable to the same sort of COUNTIF with which we developed key word searches in our Trump tweet anthology. But here you need to be careful. If I enter
=COUNTIF(“*”&”*”&”*”)
We’ll realize a count of 52, because the formula ascribes an equivalent functionality to all three asterisks – that is, a wild-card property, even though the center asterisk is the precisely character for which we’re searching. To overthrow that trammel, you need to enter:
=COUNTIF(“*”&”~*”&”*”)
The tilde signals the formula to regard the middle asterisk as the search item (see a discussion of the tilde here; I had to check it out myself). My current total of 17 (one of which is the District of Columbia) tells us that 34 states have yet to complete their presidential vote count, and this three weeks after Election Day.
It looks as if Mr. Wasserman still has a lot of work to do.