The presumptive candidate is on a roll. You have a right not to take Donald Trump seriously, but if you’re an American his name is going to be coming to a polling place near you just the same, and you’re going to have to deal with him – yea or nea.
And given Trump’s new, nearly-officialized standing as the Republican nominee for President (yes – of the United States), the time is right to take a second, updated look at the man’s tweets, the short-form vehicle of which he seems most fond. After all, a recent New York Times article called Twitter the medium that often serves Trump as his “preferred attack megaphone”; perhaps then, we’d do well to listen closely to the noise.
In the course of our first Trump-tweet review not three months ago we counted the popularity of these search terms among his immediately previous 3100 or so messages, marking the span between August 25, 2015 and February 11 of this year:
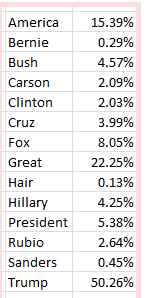
Of course the objects of some of those references have receded into past tense, but in the interests of continuity and comparison I directed my attention, and $7.80 from my wallet, to the trusty twdocs site, which happily served up a download of Mr. Trump’s last 3111 tweets (these excludes retweets), these as of the afternoon of May 10 (my time). I then proceeded to subject the above terms to a second breakout of the later tweet complement. (I’m erring on the side of neurosis, by the way, and assuming twdocs won’t like me relaying my dataset to you. This may require a DIY download on your part, then; after all, isn’t cutting-edge election coverage worth $7.80?
Keep in mind that in the interim between February 11 – the latest date of the previous batch – and May 10, Trump has transmitted new 1131 tweets, and so for starters I reproduced the =COUNTIF(tweets, “*”&A3&”*”) formula I described in this post and put it to those 1131, and found:

There have been some changes. Note the pullback in tweets referencing [Jeb] Bush, the erstwhile candidate, along with a relative spike in allusions to Ted Cruz and Marco Rubio, both of whom absented themselves from contention some while ago – developments that might be better appreciated by a timelining of the data, which we hope to build a bit later.
Of course other newsmakers have gotten themselves into Trump’s sights, including House Speaker Paul Ryan and Elizabeth Warren, the Democratic senator from Massachusetts who’s fired a few tweets of her own at the irrepressible tycoon. Yet, Trump had tweeted at these targets but five times each as of May 10, though the Warren total has since been padded; Trump also seems to think her first name is Goofy. On the other hand, the appellation “crooked Hillary Clinton” finds its way into nine mini-dispatches. “Lyin’ Ted Cruz” makes 17 appearances, along with two “Lying Ted Cruz” call-outs; but the nothing-if-not-grateful Trump expresses a “thank you” in 206 of his post-February 11 tweets, or 18.21% of them all.
Now as suggested above we might want to add a bit of chronology to the look, say in the form of a matrix that associates search-term appearances with months (and here I’m widening the look to all 3111 tweets); and while this kind of two-variable breakout sounds like a made-for-pivot tables series, this time it isn’t. A pivot table won’t work here because the search terms won’t behave like obedient items in a superordinate field. Even if we enfranchise a new Search Term field and roll it into the twdocs data set there’s no plausible way in which to populate its rows, because a COUNTIF-driven search for terms will scant the fact that some tweets contain multiple words in which we might be interested – and how are we going to usefully provide for these in one cell? It’s an improbable prospect, one that all but mandates a Plan B.
And a Plan B could look something like this: because the data in this case happen to bridge the October 2015-May 2016 space, I can authorize a new worksheet instead and enter, say in B4, the word May. If I enter April in B5 I can drag on the diminutive fill handle and drag down until I reach October (we see that Excel’s built-it months custom list lets you drag backwards in time). I’ll next enter the corresponding month number down A4:A11 and call the two-columned range Month:

I’ll then return to the data set, insinuate a new column between A and B, call it Monthno., and enter in what is now B7 (Twdocs has instated the field headers in row 6):
=MONTH(A7)
And that simple instruction works because somewhere in the past three months Twdocs has engineered a most welcome overhaul of its created_at field, and its discouragingly inconvenient text entries, which looked like these:
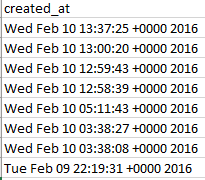
You’ll recall the gauntlet of hoops through which I had to hurtle in order to make some quantitative sense out of the above. But now the newly-capitalized Created_At looks like this:
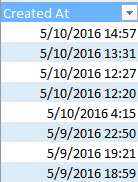
And those data, you’ll assuredly be pleased to know, are real, I-kid-you-not, certifiably crunchable dates and times (and the unvarying entries in the User Created At field portrays the date and time at which Trump enrolled in Twitter, by the way).
In any case, once that MONTH expression gets copied down its column, I can return to the Month range and stream some search terms across row 3, something like this:

Now all we need are some data, so here goes. I’ve named the tweet content field in the data set, in what is now C7:C3117, Tweets, and in C4 I’ve entered:
=COUNTIFS(Tweets,”*”&C$3&”*”,monthno,$A4)
With its multi-criteria reach, COUNTIFS grabs a month from column A and search term from row 3 realizing a tally of 10 tweets featuring the name Clinton in May. Copy the above expression across the matrix (and the $ signs appear to be properly inserted), and I get:

(Remember that the October data count begins on the 25th of that month, and the May numbers run through the 10th..You could also hide the month-number column if the presentation calls for it). Note the decisive decline in Trump references, of all things, and the precipitous contraction of Cruz-bearing tweets as well, synchronized perhaps with the latter’s folding of his tent.
Of course the matrix possesses none of the field-swapping nimbleness of a pivot table, but its formulas will auto-calculate, should the user swap search terms in row 3; and nothing prevents anyone from adding search terms across the row, once the formulas are copied into the new columns that’ll stretch the matrix as a result.
But that doesn’t mean that pivot tables couldn’t be aimed at other questions. A simple formulation could break out Trump tweets by month:
Row Labels: Created_At (grouped by Months and Years)
Values: Created_At (Count).
For the data I have, I get

Here we see that the monthly aggregates have quite discernibly shrunk, with the May pro-rated projection just about equalling the April count. I’m not sure what accounts for that development, and one wonders if Trump himself is attuned to the decline. You’ll have to ask him.
One other point: As offered in a previous Trump post, I’m nearly certain that the times in Created_At reflect my Greenwich Mean clock, and not the Trump-specific time of his transmissions. For example: a Tweet advertising Trump’s appearance on the The O’Reilly Factor television show “this evening at 8 pm” is dated 22:26.
Considered in the abstract, that discrepancy could be relieved, by subtracting an hour differential – say 5/24 – from the date/times registered in the Created_At field. For example, this date/time:
3/19/2016 16:14
Possesses the numerical equivalent 42448.68 (just reformat the value and see), representing the number of days elapsed between the above and January 1, 1900, with the .68 denoting the percent of that day elapsed. Thus a reformatted
=42448.6-5/24
yields
3/19/2016 11:14
The problem is that we can’t know the time zone in which Trump found himself for any given tweet; and as such, 5/24 might be subtracting the wrong fraction. Tweet from California, after all, and I need 8/24, – or at least I do from this latitude.
Elusive chap, this Mr. Trump, no?

Leave a comment