Ok – you think you know who won the election, but in the interests of confirmation and deep background, you want to know how the French presidential runoff vote broke in Paris, don’t you?
Well, if you’ve made it this far, one supposes you do. The May 7 mano a mano – kind of – between Emmanuel Macron and Marine Le Pen culminated predictably in a flat-out triumph of the former, in both country and city, but even the obvious is properly reducible to its details.
You don’t need my pivot tables to learn that Macron won 89.68% of the determinate Paris vote (i.e., some other ballot casters voted but threw their support to no one via an empty form, and other ballots were voided), sustaining his hegemony in the city over his right-inclining opponent. But for the deeper background (and again thanks to the folks at Open Data Paris) the data are here:
Election Results – Paris May 7
You can also download a far larger compendium of Paris election votes dating back to 2007 here.
Our workbook is identically organized, really an extension, of the document at which we looked in the previous post; but since of course the candidate count in our present iteration comes to two, the ensuing sheets look correspondingly sparer. Thus we can rerun this pivot table, after I named the prolix header in N “Candidate Vote”:
Rows: numero d’arrondissement 01 a 20
Columns: nom du candidat ou liste
Values: Candidate Vote (by % of Row Total; turn Grand Totals off).
I get, this time:
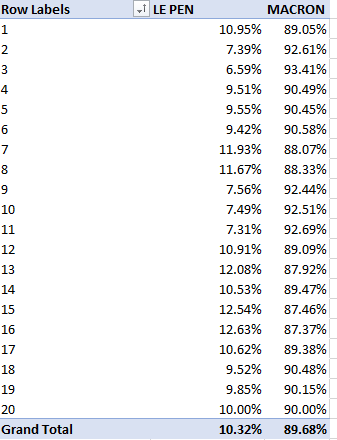
The table reports the overwhelming but irregular Paris mandate for Macron; considered in reverse, we see a comparative cresting of support for Le Pen in the well-heeled 16th arrondissement and the adjoining but Left-Banked 15th, and her bottoming out in the relatively hip, gentrifying 3rd.
How do these outcomes square with the election’s first phase, run through on April 23rd? Of course that competition distilled eleven candidacies into May 7th’s two, and so a like-for-like retrospection need be conducted with some care. Still, we can play a useful trick on the April 23rd data, by compiling an identically-conceived pivot to the one above, filtering the numbers for Macron and Le Pen alone. Thus slimmed, the table proceeds to regard the Macron-Le Pen vote as the operative whole, and computes its percentages accordingly.
That is, we can return to the previous (April 23) worksheet data, reconstruct the above table, and isolate Macron and Le Pen. I get:

Remember that Macron won 34.83% of the Paris April 23 vote overall, with Le Pen’s haul figuring to 4.99%; here their head-to-head relationship restores a couple of percentage points to Le Pen relative to the second vote; presumably her loss of ground in the finale speaks to the greater support thrown to Macron by the sectarians of the nine also-rans in the first go-round, and the decrement is fairly consistent across arrondissements. One glaring, provocative exception: Le Pen’s fall-back from 16.33% to 9.85% and a similar differential in the “ethnic” 19th and 20th respectively, these heavily Jewish and Muslim quarters. In light of those demographics, it’s the April 23rd figures that give cause for surprise.
As for turnout, the analysis starts with a decision, or set of decisions, about definition. Does turnout emerge by simply dividing registered voters by all candidate votes, or do you toss in blank submissions (Nombre de blancs (uniquement) du bureau de vote), as well as ballots that, for whatever reason, were voided (Nombre de nuls (uniquement) du bureau de vote) along with proxy (presumably absentee, or Nombre de procurations du bureau de vote) ballots?
We broached this question in part in the previous post, but didn’t think the matter completely through. There we applied a formula that took into account the multiple counting of most of the parameters above, because each entry among the data recorded an individual candidate vote for a particular polling place, but at the same time repeatedly listed the number of blank votes, etc. – one listing for each of the eleven candidates on April 23.
In fact a simpler work-through appears to be available. On the May 7 sheet we can simply scoot to the bottom of the data set and enter a SUM function in cell N1794, thereby totalling all candidate votes. We can then enter SUMs in row 1794 for the other pertinent parameters and divide these results by 2, the number of times each polling place appears in the data set – that is, once for each remaining candidate (and yes, we could do the same for the April 23 data, dividing instead by eleven). But remember that the candidate-vote numbers in N are not subject to the divide-by-two restorative, because each record in N details a unique vote figure.
If then, we want quantify turnout via the number of candidate votes/number voters registered (nombre d’inscrits du bureau de vote, and yes; these are text entries that need to be converted back into values), we simply enter (somewhere) =N1794/H1794. That figure: 72.76%. The corresponding proportion for April 23: 82.71%, clearly, and notably, higher. The percentage of blank votes turned in this past Sunday: 4.44%, five times the .82% accumulated on the 23rd. A statement was thereby made.
Now if we want to break out turnout by arrondissement – say here by dividing actual candidate votes by registrants by district, I named the arrondissement-bearing range in C2:C1793 arr, jumped into the free cell in S2 and entered 1, notched a 2 in S3, and filled down to S21, yielding numbers 1 through 20. In T2, then, I tried this formula:
=SUMIF(arr,S2,N$2:N$1793)/(SUMIF(arr,S2,H$2:H$1793)/2)
The expression sums all candidate votes (in N) by the 1st arrondissement, per the entry in S2. It divides that total by all polling-place registrants in the 1st, again dividing itself by 2 to offset the double-counting of each place (the votes in N don’t’ require that adjustment, because each record report a unique vote figure). After copying the formula down, I realized these turnout percentages:

In line with the April 23 data, the 19th and 20th exhibit lowest turnouts, even as we’ve operationalized them here.
For an index of sorts of disaffection, we can then calculate the blank-vote percentages, e.g.
=SUMIF(arr,S2,O$2:O$1793)/2/(SUMIF(arr,S2,H$2:H$1793)/2)
Note that here both numerator and denominator divide themselves by 2, because both elements need to fend off the double-count spectre (and note the placement of parentheses). I get:

Correlation between candidate vote turnout and blank vote proportions: -.54, pretty substantial and not shocking. After all, a preference for he, or she, bespeaks by definition a non-preference for no one.
So just to confirm, then: he won.

Leave a comment