Thinking twice about cleaning the bedroom – you know, that bespoke chamber of horrors heaving in entropic fury, the one housing the bed on which you sleep – somewhere? If you are, then how many times would you think about cleaning New York playgrounds and parks?
How about 880,000, the number of tidy-ups the city’s Sanitation Department performed on its recreational spaces for the 2015-16 fiscal year? Mighty big number – but even so, they don’t do windows.
They do just about everything else, though, and a canvass of those 880,000 (more or less – please read on) contributions to New York’s civic betterment that have been carted into the data set on the city’s open data site may inspire you to consider haulage as a next-career move. (You’ll understand I’m much too nice a guy to force WordPress to absorb 130 MB worth of download from a greedy subscriber. You’ll need to get this one yourself, I’m afraid; just click the Download button on the above link, opting for CSV for Excel or CSV for Excel (Europe), the latter presumably flipping day-month entries in order to comport with regional defaults.)
But even if you put your CV on hold, the still data have something to say, though their fields call for a spell of reflection before you proceed, apart from the necessary auto-fitting of the several date fields. Indeed – your reflection may need to be rather sustained.
If, for example, you want to break out the task activity by New York’s five boroughs – and you probably will – you may want to extract the borough codes from the gispropnum entries in column A: B=Brooklyn, M=Manhattan, Q=Queens, R=Richmond (the official name for Staten Island), and X=Bronx (you may want to consult the helpful field descriptions here). It seems to me that convenience could be served by deleting the propid data in B (these code the city properties on which work was performed, but may not contribute substantively to your analysis, though you may decide otherwise), renaming the field Borough, and entering in B2
=LEFT(A2,1)
Copy the expression down B and the borough information readies itself for grouping, after which you could presumably run a Copy > Paste Values on the B results and delete A, again in the interests of economizing. You’ll also of course observe the Null entries, which presumably report on activities not carried out on site, e.g., Staff Pickup and Lunch.
You may opt for additional field deletions as well in light of the workbook’s size, and the corollary understanding that each such deletion will relieve the book of about 880,000 data-bearing cells. You may have little use for the vehicle_number information, for example, and perhaps route_id, though I suppose both dislodgings may have to be thought through.
But there are deeper concerns. One might want to begin simply, by pivot-tabling task totals by month of the fiscal year:
Rows: date_worked (grouped by months and years. Remember that this fiscal year was booted up on July 1, 2015)
Values: date_worked (% of Column total. You may want to turn off subtotals, and certainly Grand Totals, as the latter will ineluctably add to 100%).
I get:

Note the apparent, pronounced pullback of activity in September – though I don’t know why – and the orderly step-down in work from March through September, though of course that trajectory plots a seasonality course that runs backwards against the actual yearly grain.
But that read isn’t necessarily that simple, or that accurate. That’s because a good many of the records seem to cite tasks that don’t quite qualify as an actual cleaning chore, e.g., lunch, De-Mobilization. So here’s a plan B: install the activity field in both the Columns and Values area, and in the latter, filter all activities save the one termed Work, which seems to serve as a catch-all item for…actual work on the parks. Continue to impose % of Column total on the values, and I get:

Once we’ve so trim the activity data – a retrenchment that abridges about 174,000 records from the whole – the monthly distribution redraws its curve. The conspicuous disparities bulge around July and August, each month here grabbing nearly two additional percentage points from the other months, even as the two September figures hold fast. Thus the obvious task-distributional suggestion – that non-work activity somehow features more numerously in July and August – remains obvious; but accountings for the numbers are not. I’m open to suggestions.
In any case, once we’ve put the work item in its place we could key the tasks to their boroughs, by exchanging the Borough field we fashioned earlier for date_worked. I get:

(Remember that N signifies the NULL entry.) It is perhaps notable that the assignments seem to have been similarly distributed across four of the city’s boroughs, with the far-less-populous Richmond well back. But these likenesses call for a deeper think, however, because they need to reconcile population (and of course Manhattan’s effective daytime census enormously exceeds its residential cohort) to aggregate park/playground counts and areas.
And what about the time expended on the tasks, again proceeding with the work-item filter as above? Here a New York open data field legend enters an important qualification about the nhours field: “A count of the adjusted number of hours a given task was performed [my emphasis].” You’ll see that for some instances – say row 43, a task whose start-to-end times evaluate to 35 minutes but is yet recorded by nhours as .292 hours, or 17.52 minutes – the lower estimate may reflect the simultaneous efforts of two workers, even as compensation of course would require the higher figure.
Going with nhours, then, we could replace activity in Values with nhours and format the resulting sums accordingly:
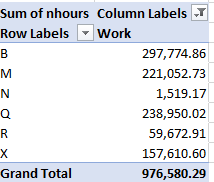
You’ll note that even as the task numbers stood as near-equivalents for Queens and the Bronx (the latter again represented by the letter X), work in the former borough seemed considerably more time-intensive.
Again, I don’t know why, but I’m just a spreadsheet guy, after all; if you want that Pulitzer you’ll have to take it from here.

There is no link to the data on the post. Can you please provide one!?