Sloth has its limits. I had, if you must know, entertained a couple of questions about the way in which I managed the New York City math test data in my previous post, but place momentum in the service of lassitude and I decided that for the time being I couldn’t be bothered. Now I’m bothered.
What’s bothering me, at last, is a concern we’ve certainly voiced before in other posts – namely, the fact that my score analyses to date have ascribed equal weight to each record in the data set, irrespective of the number of students populating the listed schools. That forced parity thus imparts disproportionate influence to smaller schools. But because the data set is so sizable, I had originally assumed that a proper weighting of the student populations would exert only a small corrective effect on the test averages.
That assumption isn’t terribly untoward; but because the girls’ test averages evince only slight – if tenacious – superiorities over the boys’, a second, suitably weighted look at the scores might the responsible view to take via a calculated field, in the interests of learning if the results might materially change as a consequence.
To start, then, I visited next-available column S, titled it RealScores (of course the name is your call), and entered, in S2:
=IF(H2=”s”,””,F2*G2)
The formula simply multiplies every school’s mean score in G by the number of its students posted to F, returning the total number of score points, as it were, to be divided by the total number of students identified by a pivot table breakout (e.g, Borough).
The IF statement in which the formula is couched replaces each “s” entry (see the previous post below for explication) with a textual cipher (“”), and not 0. That latter numeric would have been processed by any average, thus artificially depressing the results. And the absence of a test result assuredly does not strike an equivalent to zero, as any student will tell you.
And those “s” rows release an interesting subtlety into the equation. The calculated field, which I’ve I advanced above (I’ve called it actscore) is written thusly:
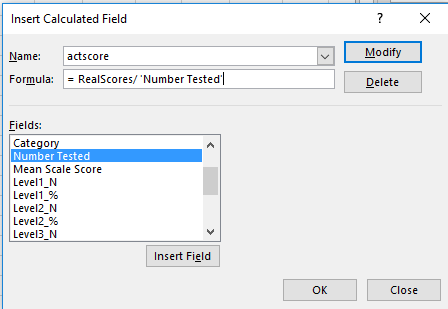
That is, the field simply divides the RealScores field we instituted earlier by the total number of students tested (the Number Tested field). The “s” records contain no scores – but they continue to cite student numbers in Number Tested. Unaccompanied as they are by no scores, those numbers thus add ballast to the denominator in our calculated field, and in turn artificially drag down the averages.
The way out – one way out – is to sort the Mean Scale Score (in G) Smallest to Largest, if you’ve clicked on a number in the field. The s entries should fall to the bottom of the field, the first s landing in row 36045. Hang a left to F36045, enter a 0 there, and copy it down the remainder of the column. Now the calculated field will add nothing from the s records – literally – to the Number Tested denominator, obviating the downward pull of the averages to emerge.
Got all that? In any case, now we can go on to construct the same pivot tables that featured in the preceding post, and compare the new recalculated results here with those in that post.
Averages by Gender and Year:

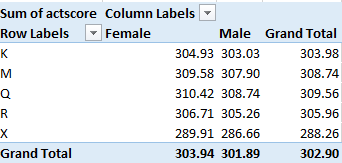
Averages by Borough and Gender:
One we didn’t directly bring to the previous posts, Averages by Grade and Gender (we had added Year to the mix there):
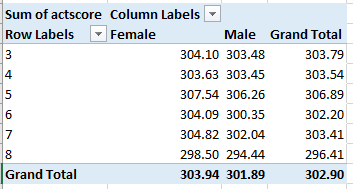
The signal conclusion here is the preservation, per all permutations, of the girls’ edge. The averages are all a touch higher this time around, however, a concomitant of higher scores that appear to obtain in the larger schools – the ones contributing larger numbers to the averages.
Now I’m not so bothered. But I’m still missing a sock.

Leave a comment