House hunting? Then why not think about setting up stakes in Burlington, Vermont? Bucolic but sophisticated, a university town festooned with postcard-perfect New England autumnal foliage, lovely this time of year… and the very city in which Ben and Jerry’s Ice Cream was founded.
What more could you want? But the real reason I’m so keen on Burlington – a city I’ve never actually visited, after all – is its spreadsheet-archived history of property transactions, a veritably sociological, 100-plus-year account of the residential flux of its citizenry, available to you on Burlington’s open data site, and here, too:
All of which begs a first question about those 100-plus years: how complete is the sheet? Once you’ve done the column auto-fit thing, if you sort the data A to Z by column G – Sale_Date, whose holdings presently appear before us in text mode, you’ll observe that the three transactions in the data set lifted to the top of the sort are dated January 1, 1800, and succeeded by another seven sales, each of which was apparently conducted on July 14, 1897. Add the exactly twelve property purchases agreed upon in the 50s and the 21 more ratified in the following decade, and the market is starting to look a little sluggish, isn’t it?
I’m no developer, but I’m a speculator; and I’m speculating that the sales record as we have it must be partial, for whatever reason. I’m also conjecturing that the Sales Prices (column H) amounting to $0 denote a property bestowal of sorts, perhaps from a charitable donor to a governmental entity. In fact, I put that $0 conjecture to the Burlington open data site, and await their reply.
And in light of those sporadic sale representations it might be sensible to confine our analytical looks to the records commencing with 1990, because purchases in the 70s number a none-too-profuse 41, and the sales count for the 80s – 137 – appears questionably scant as well; and so it seems to me that a first analytic go-round, at least, might sensibly push off at 1990, the inception of the decade in which the data uncork a quantum leap in activity. But needless to say, a reportorial consideration of the property sales would force a closer look into the pre-1990 lacunae.
That’s one issue. For another, inspect the Sale_Date entries in column G. As adverstised, each and every one of these appears to be textual, encumbered by the T00:00:00.000Z suffix that entraps the real, immanent dates in their cells. But a fix is available (really more than one is out there): select column G and apply this Find and Replace:
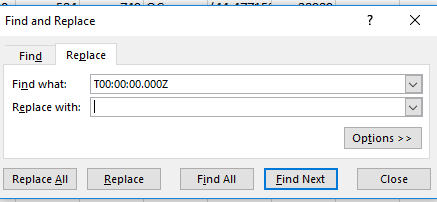
Replacing the suffix with nothing at all frees the actual, quantifiable dates within each cell, and even restores the results to my American regional date settings, in spite of their year-first formats.
But you may notice nine recalcitrants to the above workaround – the sale dates preceding 1900. They’ve shed their T00:00:00.000Z appendages but remain steadfastly textual; and that’s because Excel can’t directly process, or quantify, dates falling before January 1, 1900 (for some suggestions for allaying the problem look here). In light of the discussion above, however, that sticking point won’t adhere here, because our intention is to ignore sales predating 1990 anyway. But at the same time leaving those insistent textual entries in the data set will effectively stymie any attempt to group the dates in a pivot table; throw even one text datum into a date mix and you just can’t group it, or at least I can’t. Thus if you click on any date in the Sale_Date field and sort Oldest to Newest, the nine textual charlatans drop to the bottom of the column, whereupon one can thread a blank row immediately above them, and break them off from the remainder of the data set.
The larger question – albeit an academic one here – is to ask about a strategy for contending with say, a few thousand pre-1900 dates among the data, had they been there. With a number that large, we would want to use them – but then what? The simplest tack, I think: not to run the Find and Replace, then, but rather draw up a new field in the next-available N column, call it something like Year, and enter in N2:
=VALUE(LEFT(G2,4))
and copy down N.
The reason we’d look past the Find and Replace here is because the above formula will return the pre-1900 postings as simple numbers, e.g. 1800; and 1800 doesn’t represent the year 1800. It stands in fact for December 4 1904, the 1800th day of the sequence commencing with the date baseline January 1, 1900 (and we’ll ignore Excel’s February 29, 1900 willful error taken up in the article linked above). In the interests of consistency, we’d want to regard the all the data in G one way or the other: either as bona fide dates or unvarnished numbers – and if we found ourselves working with pre-1900 dates we’d have to resort to the latter plan.
But again, because in our case the pre-1900 data are so negligible we’re ignoring them, and reverting to the actual date-making Find and Replace scheme. All of which at last enables the answer to an obvious research question: how many Burlington properties have been purchased by year?
Start with this pivot table:
Rows: Sale_Date
Values: Sale_Date (count, grouped by Years. Click the Filter button by Row Labels, tick Date Filters, and enter
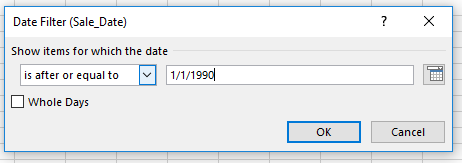
I get:

Note that the above Grand Total and its record complement date only from 1990, but nevertheless encompass 28790 of the 29032 entries packing the entire data set (note in addition that the 2017 data take the sales through September 15). The activity curve trends this way and that, with the numbers peaking in 2003 and scaling down erratically in the intervening 14 years (though all this of course assumes the data are complete for the respective years in hand, an unsubstantiated but not implausible guess).
We next might want to pursue a natural follow-up: an association of average purchase prices by year. But here too some forethought is needed – because by admitting the raft of $0 “purchases” into the calculations the averages would skew badly. We could thus apply a simple fix: take over the next free column (probably N; remember that the earlier data settlement in that column was hypothetical), call it Nonzero, and enter in N2:
=If(H2>0,H2,””)
H stores the Sales_Price data, and the “”, or length-less text double-quotes, will be ignored in any average computation. Once we expand the pivot table data source to N we can garnish the existing table with Nonzero, Average, and figured to two decimal points. I get:
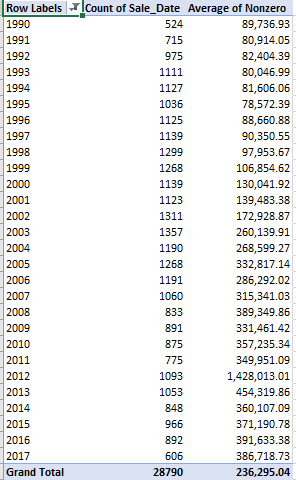
Unlike actual sales, the average prices proceed more or less upwards, an unsurprising ascent syncopated by the spike in 2012. Filter that year in the data set and you’ll find four identically described and dated purchases of $6,485,000, conducted on December 18 of that year by the Bobbin Mill Building Company and sold to the Burlington Housing Authority. A sweeping property acquisition by the powers that be, or a data-entry redundancy? I don’t know. And I haven’t come across any Land_Use and Deed_Type legends that would decode the entries in those fields, and that could inspire some additional breakouts of the data.
C’mon, Burlington, help me out here; give me those answers and there’s a Double Caramel Brownie Ben and Jerry’s cup in it for you. With an extra scoop – my treat.

Leave a comment