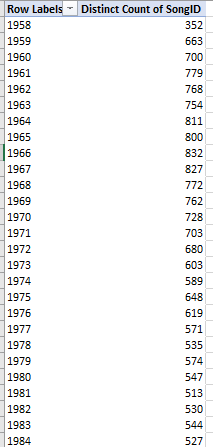Like American presidential elections, the World Cup doesn’t seem to end; the four-year interregnum separating those two events seems ever more ostensible; and because some prognosticators have instated Brazil as winners of the 2022 Cup it may already be time to wonder if the tournament should be held at all.
But my latest information is that it’s all systems go, and anyway, Qatar is lovely in November; so in the interests of limning some helpful deep backgrounding of the picture, you may want to download and kick around the data set of all World Cup match outcomes extending through the 2014 go-round, niched here in Kaggle’s repository of holdings.
The set then records all 836 matches contested from the Cup’s inception in 1930 through the immediately previous competition, in relatively self-evident fields, with the exceptions of the Round and Match IDs in columns Q and R. Kaggle maintains that the identifiers are unique, but the Round IDs exhibit a qualified uniqueness, i.e., they appear to signify a certain stage in the tournament (e.g. semi-final) that by definition would have been reached by multiple teams bearing the same id. And the match ids display curiously variable lengths, suggesting a mid-data shift in their coding protocol. The 2014 matches, for example, sport nine-digit identifiers; in 1998 their lengths have shrunk to four characters.
More troublesome is the small but measurable number of redundant game records, signaled by shared match ids. A Remove Duplicates routine earmarking MatchID as the offending field discovered 16 doubled records, which were promptly shown a red card.
Once you’ve stretched all the columns via the requisite auto fit, you can begin to think about what’s interesting in here. What, for example, about putative home field advantage? That vaunted residential edge is something of a legal fiction here; the first record, for example, names France as the home team and Mexico as the visitors, in a 1930 game set in host country Uruguay. But that only nominal imputation spices the question; might even a desultory home team standing impact game outcomes?
Let’s see. Any formula presuming to calculate win percentages needs to reckon with a common soccer/football eventuality – the fact that many games culminate in a draw. As such, we can take over next-available column U, title it Home Win Pct., and enter in U2:
=IF(G2>H2,1,IF(G2=H2,0.5,0))
That simple expression means to ask: if the goal entry in G exceeds the figure in H – that is, if the home team wins, then enter 1 the appropriate U cell. If, however, the values in G and H are identical – signifying a draw – then assign .5 to the cell, the standard evaluation of an outcome in which each team in effect arrogates half a win. Once we copy the formula down U, we can simply add all the numbers and divide the total by 836, the number of records in the data set (remember we deleted 16 of them). The result: a home-team win percentage of 68.42, a disproportion that piques the question as to exactly how home teams are nominated.
For example: in the 1930 debut Cup, Argentina received home-team standing for four of its five matches, its sole “away” status assigned to its role in the final, which it lost to the authentic home team, Uruguay. Mexico, on the other hand, competed under the away rubric for all three of its games that year. And the home team in 1930 – however denoted – won all 18 matches during the tournament.
Explanations notwithstanding – though they do need to be pursued – we can calculate Cup-by-Cup home-team winning percentages via a rather neat deployment of the AVERAGEIFS function.
First, enter a bare section of the spreadsheet and list the years in which the Cup was held, starting with 1930 and coming to a stop at 2014 (I’m commencing in Y3). Once you type 1934, of course, you can drag the remaining years down their column by autofilling their four-year interval, remembering, however, that the Cup was suspended in 1942 and 1946. Then name the Year field in A yr, the winner field in U win, and enter in Y3:
=AVERAGEIFS(win,yr,Y3)
And copy down the Y column.
How does simply averaging the win data – which after all, comprise either a 1, a .5, or a 0 – forward our objective? Contemplate this example: a team winning two games and losing one receives 1, 1, and 0 points for its exertions. Average the three values and the resulting .6667 returns the winning percentage for two wins and one loss.
If we’re happy with that understanding and then proceed to format the results in percentage terms, I get:
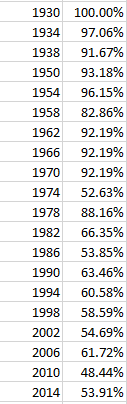
It is clear that somewhere, perhaps in the 70s, the idea of a home team underwent a rethink; I’m not sure what drove the apparent definitional overhaul, but it seems to have been put into place (for a possible partial accounting see this discussion). We even see an away-team edge gained in the 2010 Cup. I’m happy to entertain surmises about these disparities.
In any case, what about goals – e.g., have their outputs ebbed or surged across the Cups? If we want to figure a winning-to-losing team metric, say the average winning and losing goal total – or really, the average score – by game by Cup, we’ll have to improvise, because those data aren’t expressed in existing fields. A couple of simple formulas should be able to answer our question, however. I’ve moved into column V, called it Win Goals, and jotted in V2:
=IF(G2>H2,G2,H2)
That expression simply declares that if the goal total in G exceeds the one in the corresponding H cell, then return the value in G; otherwise report the number in H. If a game was drawn the logical test will not have been met, of course, but no matter; since in such a case the G and H figures are identical it matters not which one the formula returns.
I next head into to column W, label it Lose Goals, and write what is in effect the flip side of the above formula in W2:
=IF(G2<H2,G2,H2)
Both formulas are copied down their respective columns, of course, and conduce toward this pivot table:
Rows: Year
Values: Win Goals (average, formatted to two decimals)
Lose Goals (same treatment as above)
I get:

The marked downturn in goal scoring is associated with the recency of the Cups; indeed, the overall winning-game average of 2.18 goals was last attained in the 1970 tournament, and the average victory margin of three goals in the 1954 contests exceeds the average per-game combined goal total for the last 14 Cups. Average winning margin for all games: 1.51 goals.
And let’s see VAR verify that .51 goal.