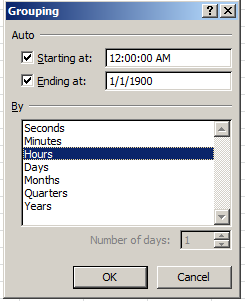
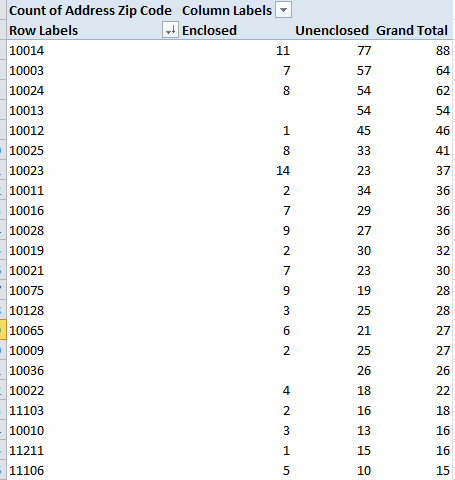
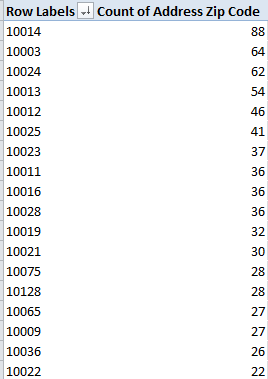Allow me to refresh your memory. When we last eyed each other across our respective devices I closed our tete-a-tete with a bit of a pivot table cliffhanger, although I can’t say I’ve seen any of you inching towards the edge of your seat in melodramatic thrall. But cheap production values notwithstanding, the problem was this: our attempt to group the NHS hourly data into tranches of three hours met with what appears to be a you-can’t-there-from-here rut in the road: the apparent fact that Excel’s grouping resource won’t extend its functionality to time-formatted values , e.g:
(In fact units of time can be grouped, however, after a limited fashion. For example, these times – 8:17, 8:31, and 8:54 – will submit to a manner of grouping, all massing beneath the 8:00 rubric. But grouping times across discrete hourly readings – for example, collecting 9:17, 10:12, and 11:32 into a 9:00-12:00 bin – appears to be a non-starter, though I am happy to be corrected should I be missing something.) What to do, then?
Here’s a tack that seems to tread the path of least resistance. Insert a column to the immediate right of the Hour of arrival column in A, call it say, Hour, suit it up in Number format, and enter in what is now B4:
=A4*24
That elementary operation multiplies the time value in A4 – in this case, 0 – by the 24 that casts the hour numbers onto firmer ground. But a zero result doesn’t really capture the point, and so copying the formula down B and considering the workings of B5 – which yields 1.00 – should serve to explain more definitively.
Remember that hour data are expressed as fractions of a 24-hour day. Thus the actual numeric persona of the 1:00:00 AM in A5 is .0417, or 1/24th of 1 – a whole day. 09:00:00 AM, by way of continued example, is ultimately nothing but .375, or 3/8th of a day, and so on. Multiply .375 by 24 and you get…9, a solid numeric stand-in for that .375; but because the 9 is a standard number, it can be grouped as such.
Thus copying our formula down B delivers a set of illusory but valuable numeric equivalents to time data, e.g.:
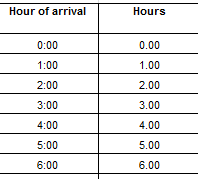
Note the B-columned data are decimal-pointed, although that formatting nicety won’t matter once the numbers are mashed into group mode – because you can’t format grouped data.
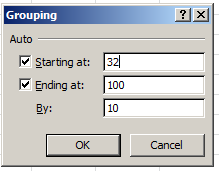
In any case, dust off a pivot table and drag Hours into the Row Labels area. Point and shoot at Group Selection, and say hello to the By option:
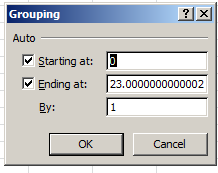
Enter 3 therein and you get:
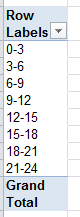
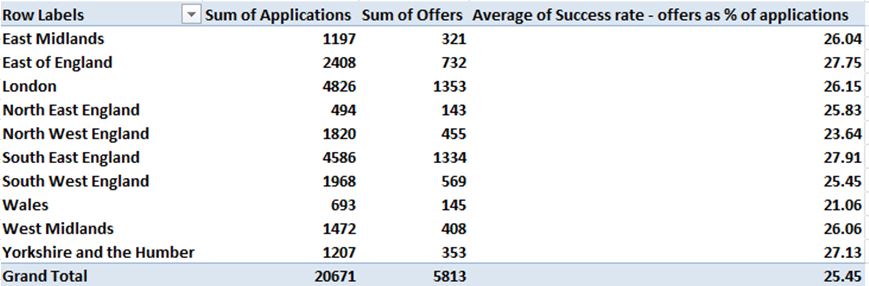
Houston, we have a grouping. Now you can swing some yearly patient data into the Values area, e.g. along with some presentable formatting:
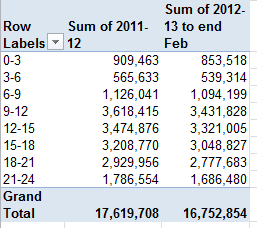
(You don’t need decimals here; we’re dealing with actual patient aggregates, not averages.)
And if you’re feeling adventurous, you could append another new column to the right of the 2012-13 data (via a column insertion; don’t occupy the existing blank column, because it separates the absolute patient data from the percent data on their right, and you don’t want to join the two), call it Projected 2012-13, and enter in I4:
=H4*(12/11)
Because the 2012-13 numbers convey eleven months’ worth of data, the above formula projects another month atop the patent totals as they stand. That’s a straight, linear per-month projection, one which might not wholly comport with a finer 12-month extrapolation, but it’s a stab in the right direction.
Now about the puzzlement at which I hinted last week, portrayed here:
I’m wondering about that 1/1/1900 default glimmering in the Ending at: grouping field – even as the Hours option has been ticked. 1/1/1900 isn’t an hour, of course, but it is the very first date fronting Excel’s date sequence, and it has the value of…1. And the Starting at: entry of 12:00:00 AM is translated into standard numeric language as…1. As intimated earlier, time-formatted data tops out numerically at 1, the limiting case-value that recapitulates a day’s entire span (bear in mind that the number 0 also stands for 12:00 AM, as it bookends the other side of a single day, if that doesn’t pose a puzzlement in its own right). Given all that, I’m thus conjecturing that the 1/1/1900 discrepancy simply substitutes for a second 12:00:00 AM, because had that latter rendering of the number 1 settled into the Ending at: field, you’d be viewing identical data twins in the two fields – and that might puzzle users all the more. As a result, I’m thinking that 1/1/1900 supplies a different data look for the sake of presentational, but not substantive difference.
But I’m happy to be corrected about this one, too.