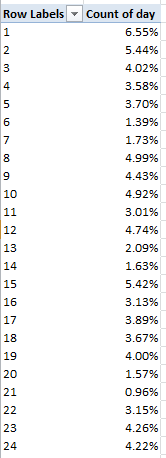In-jokes are for the in crowd, and if you’re out, you’ll click uncomprehendingly past the wunderground.com’s very name, wilfully cute shorthand for Weather Underground, and its in-plain-sight harkening to the 60s radical group by that very name.
They’re based in San Francisco, you see, where such allusions are knowingly received; but history aside, wunderground.com backlogs all kinds of information about things meteorological, and that doesn’t sound too subversive, does it? Call me a naïf, then, but I’m not mine-sweeping the data for clandestine, coded hints to the cadre; I’m prepared to believe it’s actual weather data you’re looking at.
And among many other confidences into which wunderground will take you is historical data for a great multitude of localities, and that’s good news for spreadsheet pattern spotters. Start by going here:
Type in a place name, click submit, and follow by clicking the Custom tab, whereupon you can enter from/to date endpoints (N.B. – these can be no more than 400 days apart; if you want two years of weather history, then, you’ll need to issue two Custom requests and airlift the results into one sheet, one set atop the other). Click the one of the two Comma Delimited File links at the base of the results (no; I can’t explain the need for two).The data appear in a new window in bare CSV form, and must be copied, pasted and then subjected to a painless Text to Columns routine (the separator, here: comma. Remember as well to delete the presumptive header row from the second paste, (see the January 17 post for review) shimmed smack dab in the middle of all the pasted data, if you’ve called up two years of records).
I thought I’d try out two years’ worth of data (for 2011 and 2012) on the city of Manchester, UK, whose stereotypical rep for precipitation promotes its rain to a veritable near-tourist attraction. After booking two Custom reservations for the city (Jan 1-Dec 31, 2011, Jan 1- Dec 31, 2012, in line with the 400-day request limit), I nailed this pivot table together :
Row Labels: Events
Values: Events (Count, of necessity; the data are textual)
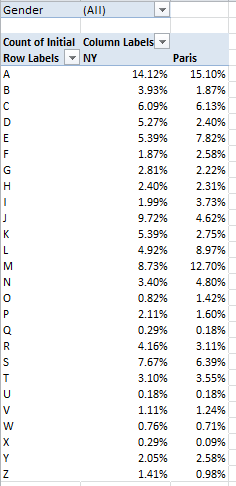
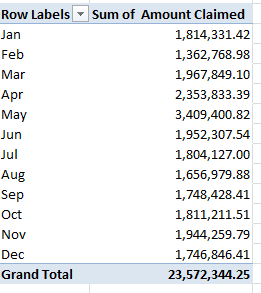
It’s in the Events field that you’ll find confirmation or grounds for pooh-poohing the Mancunian (trust me – that’s the adjective, Word’s redline notwithstanding) repute for showers-by-the-hours. I get

I see a few problems here darting between the drops. I’ve ordered 731 days of weather from wunderground (remember, 2012 was a leap year), and I’ve come away with only 520 of them. That’s what happens when 211 blanks dilute the data, and we need to ask who invited these nullities to the party. An unpopulated Events cell could communicate one of two very different things: simple data truancy, i.e., a bit of AWOL information about the day, or rather a merely quiet day – that is, one in which no recordable “event” happened in Manchester. The difference is most material; dividing 401 rain days by 520 usable days, or by 731 of them instead clearly matters; and given the profuse but unsystematic distribution of the blanks I’d opt for the latter take, that is, that the blank-bearing days were simply deemed uneventful.
And if I’m right that means we need to fill the blanks with some substantive, cell-resident indicator, so that each blank turns into something count-worthy. Here, I’d simply select the Events column and run a find and replace, entering nothing at all in the Find field and the word None in Replace. Refresh the pivot table, and 211 Nones take their place at last among the data. Now jigger Values to Show Values As > % of Column Total and:

Going to Manchester? Bring your umbrella. A run-through of similarly time-framed data for London – no slouch in the rain department, itself – ran up a rain quotient of 47.81%.
Next problem. Manchester’s Precipitationmm field (the mm presumably abbreviates millimeters) serves up an unrelieved medley of zeros, one for each and every day, among the data, and that can’t be right (the London data does carry this information, by way of contrast). That’s a clear data imperfection, in need of follow-up (I’ve awaiting an e-mail reply from wunderground on the two problems).
The third problem is data-conceptual. In fact, the data in the screen shot above spreads its rain-classificatory umbrella atop more than 54.86% of Manchester’s days; after all, if a day is reckoned in Fog-Rain-Snow terms, then among other things, it rained. We thus may want to assimilate all rain-experiencing days into one metric, and we can achieve that end by bounding into the first free column (it should be X), heading it Rain and entering, in what should be X2:
=IF(ISERR(FIND(“Rain”,V2)),”None”,”Rain”)
In other words: If the nested FIND (see the June 6 post) fails to hit upon the “Rain” in the specified cell and incurs an error message as a result, deliver the word “None” into the cell. Otherwise, i.e., the character string Rain is flagged, post Rain to said address. Copy down the column, and pivot table thusly:
Row Labels: Rain
Values: Rain (Again, Count and % of Column).
I get, then:

Make that an umbrella and a raincoat. The comparable figure for London, circa 2011-12: 52.05%. Paris? 43.23%. Er, Honolulu? 45.69%. Surprised at that last number? Me too. So is the Manchester Chamber of Commerce. Pleasantly.