There are two kinds of spreadsheets, incarnating two states of readiness – the first, all dressed up with nowhere to go but right before your got-to-know gaze – and the second, an unprocessed, unpretty, whole-fibered object whose monotonic, pedal-pointed rows ask you to hold on tight to your mouse and do something with them.
State number 2 conceals a dare: if you want to really understand what’s going on with the data, you need to bring something to the show. Stare at a sheet rattling 200,000 rows in your face and try to make some sense out of it without busting a move at the data; there is a difference, after all, between a reader and a user.
Whew – I feel better for having said that, and while I’m stoked let’s click at the brace of workbooks migrated to the public domain by the UK Office for National Statistics, counting the gender-parsed top 100 birth names in 2013 for England and Wales.
The lists made some news in England last week, but even though we’ve worked with baby name data before (e.g., my April 10 and October 24, 2013 posts) there are additional considerations to be broached. Look, for example, at the Table 1 – Top 100 girls, E&W tab in the girl-specific book (in excerpt):
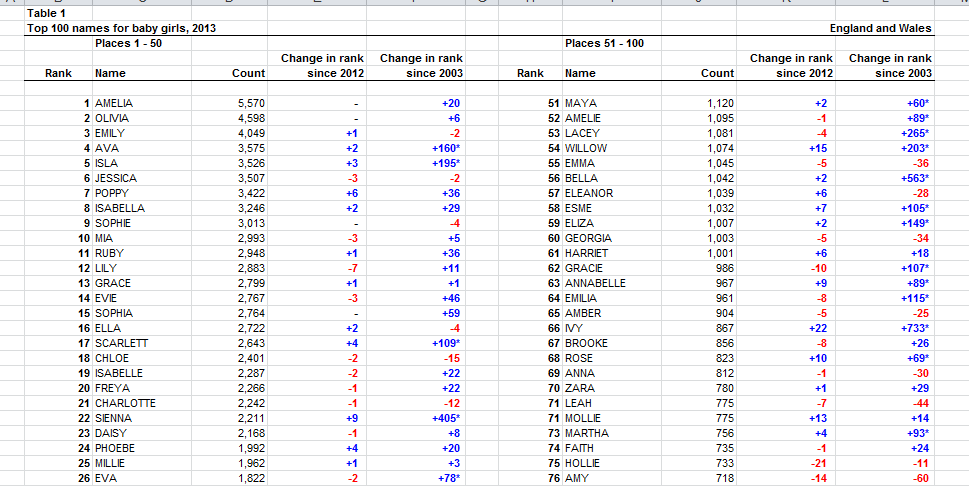
Pretty? Maybe, but look again. Why, I feel professionally impelled to ask, are the 100 names split down the middle, thus forging what are in effect two parameters comprising precisely the same kind of information, along with a doubling-over every other field? Even a sit-back reader might ask the same question; and for those who want to actually do some business here, the sheet as it stands just can’t and won’t do, and that’s quite apart from the impertinent blank row atop row 8, which should be made impermanent. And while I’m at it be advised that the Change Since… numbers attending the names are textual to a fare thee well, with authentically texted number signs in lieu of the numerically formatted kind, the occasional asterisk, and all kinds of superfluous spaces in there too. (But I’m leaving the Change data aside for the purposes of the discussion, but for the record one could reclaim their arithmetic standing through a regimen of finds and replaces and TRIM functions.)
And given the presentational morass above here’s what I do, in the interests of accessibility and maximized analytical puissance: Copy each set of Rank, Name, and Count columns from the Top 100 England and Wales tabs on both the boys and girls workbooks all into a new sheet, and then open two columns to which gender and country identifiers are to be coded, e.g.
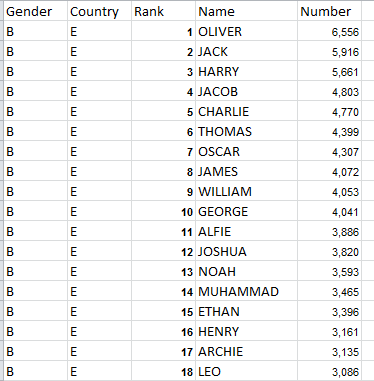
(I’ve also invested the copied data with the workbook default Calibri 11-point font for consistency’s sake.) You should wind up with 402 names (and not 400, because of some same-ranked names).
Now you can get back in touch with your inner user. Remembering of course that the data enroll only the top 100 baby names into its global denominator, we could look for example at the inter-country relation between names, understanding that overall ,Welsh babies account for about 5.3% of all births (the ratios are almost identical between boys and girls). Try something like this:
Row Labels: Name
Colum Labels: Country
Values: Number (by % of Row Total)
Filter: Gender
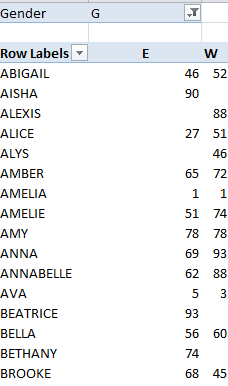
In excerpt and filtering for Girls I get:

You should be looking here for Welsh proportions departing in either direction from around 5.3%; thus Brooke features relatively more often among Wales births, but then look at Alexis, its 33 babies all born in Wales.
Now substitute Rank for Number in the Values area (by Sum):
Amelia’s trans-national appeal is clear, but you’ll note significant rank disparities up and down the results.
Now think about this: might a notable difference between average name lengths obtain between gender and/or country? It might, but you’ll be quick to call the absence of a name-length metric among the source data to my attention, and you’ll be right to do so. How, then, could name-length differentials be appraised?
And that request is a multitudinous one; and the most elemental reply to it would have us assign a LEN formula alongside each name, total the accumulation of them all, and divide it by the number of names, presumably under the steam of a COUNTA. But that won’t work, even if you’re happy with the idea. It won’t work because by having copied the England and Wales names from their associated sheets, many names thus appear twice, and as such enforce a small but measurable skew upon the calculation. The alternative here, then: bang out a pivot table, and assuming you’ve brought that Length field into the data fold:
Row Labels: Name
Values: Length (Average)
The table naturally reports each name once inside the Row Label column, because that’s what Row Labels do – return every item in the Labelled field uniquely. The necessary reversion to the Average operation above owes to the fact that, even as Amelia appears but once among the Row Labels, Values defaults to a sum of her two name lengths in the original data set – the one for England, the other for Wales, or a summed length of 12. And now you can play through the formula proposed in the previous paragraph (and if you do, I’d keep away from those GETPIVOTDATA references that’ll beset the expression if you click on the cell references; I’d just type the refs in standard mode).
That should work, at least mathematically. But you may be happier with a weighted assay of the name lengths that commensurately honor the variable numeric contribution of the names. After all, average the lengths of Abigail – the choice for 1191 girls – and Alys, the name adopted by 59 sets of parents, and it comes to 5.5. But is that how you want the average to be understood? And if you don’t, and you’ve been won over by the prospect of a weighted average, can that end be pursued with one formula, and without bothering to institute a Length field in the data set?
The answer is yes, and the formula – at least one such formula – looks something like this:
=SUMPRODUCT(LEN(D2:D403),E2:E403/SUM(E2:E403))
(assuming the Names occupy D, with the number of births moving in next door to E). And so it seems to me then that we need a part two, so think about what you see above. But remember you can always speak with me during office hours. I think they’re Wednesdays 11:12:30 and by appointment.

Leave a comment