Don’t bother looking; the year-end men’s tennis rankings are in, and I’ve failed to crack the top 100 – or even a few orders of magnitude beyond, if you insist on shining the flashlight on the whole list. I’m searching for a new coach but Ivan Lendl won’t take my calls, and I remain open to suggestions.
But if you need to know the names of the boys in white who did manage to serve-and-volley their ways past yours truly, check out the CoreTennis site’s Association of Tennis Professionals (ATP) listings for men, along with the Women’s Tennis Association standings, too. Here’s the men’s file:
(You’ll probably want to untie the ribbons on the wrapped text in there and refit the columns, too.)
Now while the players are ranked indeed, the measure by which they’re ordered – the number of matches each contested – doesn’t quite seem to make the point. Are the best players those who simply step onto the court most often? I would think not, at least not invariably, though it makes considerable sense to suppose that players who’ve plied more matches are the ones who’ve likely gotten farther into the tournaments in which they’ve appeared. Or a large match quotient might tell us little more than the player’s determination to slot more tournaments in his diary. In fact, the correlation between a player’s match total and his winning percentage (the PCT field) works out to .681, impressively high to be sure, but not invariable. In any case a click of most of the headers will grant a re-sort of the data by that field instead (and note the pasted, sortable headers preserve their hyperlinks back to the CoreTennis site, and as such will respond to clicks in their cells with a return to their web sources. By creeping into the first link-bearer via the mouse and selecting the all others with a Shift-right arrow, click-free feint, and right-clicking the Remove Hyperlink option, unimpaired, standard cell editing will be enabled anew, however).
But the decision to sort the data by matches played is more editorial than operational, as is the confining of the dataset to a 40-player elite. So if you’re looking for something operational , then, look at the PCT field and its train of leading zeros. One runs into this supererogation rather often, and I don’t quite know why the sheetmeister here couldn’t have served up this custom format:
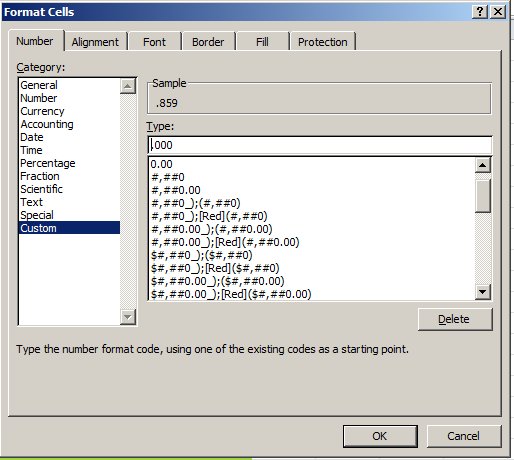
(Warning: tennis-themed pieces are dangerously pun-provocative. I’m trying to control myself, but no promises.)
Moreover – and this is an operational quibble, and a not entirely fair one here – it seems to me that the analyst, again as opposed to the reader, would be able to shape the data set sans any ranking field at all. And that’s because a pivot table can rank its contributory fields with the Show Values As > Rank Largest to Smallest/Smallest to Largest option as needed. But of course CoreTennis can’t be expected to capitulate to the spreadsheet lobby on this count.
Now about those headers, in particular three of the last four:
![]()
The source data don’t read that way, or course – so what’s happening here? Remember that, as with last week’s post, I simply copied-and-posted the rankings to my local spreadsheet (and by the way, appearances to the contrary, the data do not fill an Excel table, in that term’s contemporary sense; they’re nothing but a data set, all snug in their columns and rows), and the recipient cells have chosen to treat the headers as dates. Thus Excel reformats the first of the problem headers, natively headed 6-0 (and totalling the matches the player won six sets to none), into June 1900, the reckoning my US-date-formatted system assigns the expression. You want to see 6-0, though, and perhaps the simplest restorative is to type the Neolithic, text-defining apostrophe into the cell and simply re-enter 6-0, and repeat for the remaining dated cells. Note on the other hand that cell H1 – the one recording the 0-6 header – is, and always was, a texted thing, because if Excel regards the 6 in 6-0 as June, it can’t regard the 0 in 0-6 as anything at all. And when all else fails, the torpid text format jumps right in.
And had CoreTennis asked me, and rest assured they didn’t, I would have reassigned those three-lettered player country designations to a field all their own, and so freeing those data up to some useful pivot tabling. But as those abbreviations share a space with their citizens’ names, we might want to think about a formulaic extraction of the country codes.
And that’s a job for the MID function, a device I recruited in this post to extricate two-digit month identifiers from larger expressions. Here the task is a touch more formidable, because we don’t know exactly where in the respective player/country cells the county codes start. So here’s one – and just one – stab at the problem, working from cell K2 and literally addressing Roger Federer’s info in B2:
=MID(B2,FIND(“(“,B2)+1,3)
Here MID outsources its second argument – the character position at which the extraction is to commence – to FIND, which discovers and enumerates the whereabouts of the open parenthesis/bracket, in turn always one character to the left of the inception of the country code 0, and thus accounting for the +1. The final 3 instructs MID to grab that many characters from the cell, as all the country codes comprise precisely 3 letters.
Once you get that going, copy the formula down the K column (which I’ve field-named Country). Now you can pivot table a country breakout, e.g.
Row Labels: Country
Values: Country
Sorting the numbers from Largest to Smallest I get:
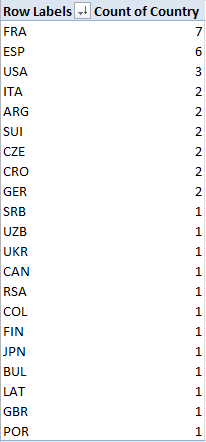
France leads the country representation, and that’s Spain (Espana) counting one less player (the women’s top 40 leads with the USA and Czechoslovakia, with five entries each. You could then slide the PCT field into Values, summarize these by Average, and subject the numbers to the same customizing pictured in the first screen shot up there:
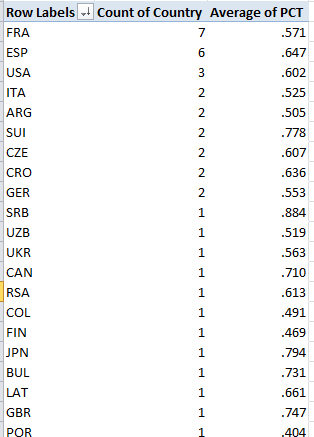
(Remember the numbers above average different players’ percentages, and as such don’t weight these for numbers of player matches played. But, those numbers are sufficiently close to accord them weighting parity, and in any event there may be good reason here to treat the individual percentages as equally contributory). Note Serbia’s (SRB) chart-topping .884. That kudo of course belongs to Novak Djokovic, but he’s a universe of exactly one. Needed here: more players to rank. And if you want to see my name in there, needed here: Ivan Lendl.

Leave a comment