Don’t touch that dial, and hands off your mouse wheel; it isn’t déjà vu that’s spooking your reverie but rather another look at the UK’s 2014 Research Excellence data, this one pictured by an extensive piece in the Times Higher Education magazine’s January 1-7 issue. THE (the acronym, not the article) makes considerable room across its pages for a subject-by-subject, peer-judged drilldown of the research impact unleashed by the country’s university departments, an expository angle that points it quite a few degrees from the Research Fortnight study of university funding prospects and their relation to the Excellence figures that we reviewed a couple of posts ago (and thanks to Fortnight’s Gretchen Ransow, who sent me RF’s original data in its pre-Guardian/Telegraph/Datawrapper state).
Impact? It’s defined by THE, at least in the first instance, by a department’s GPA, or grade point average – a summatory index of department staff research activity scored on a 1-to-4 scale, the higher the more impressive. The foundational calculus is pretty off-the-shelf:
(4s x number of staff so achieving+3s x number of achievers+2 x number of achievers+1 x number of achievers)/count of all staff
Thus a department of 20 members, 10 of whom are adjudged 4-star researchers and 10 pegged at 3, would earn a GPA of 3.5. But because departments were free to submit just the work they elected and were equally freed to detain other researches from judgemental view, THE coined a compensatory intensity-weighted GPA, arrived at after swelling the above denominator, by counting all staff whose work could have been slid beneath the REF microscope, even if these were kept off the slide, for whatever reason. If the above department, then, had 30 eligible assessment-eligible instructors in its employ, its intensity-weighted GPA would slump to 2.33 (its 70 grade points now divided by 30; of course, a department’s intensity-weighted GPA can never exceed its GPA, and can only match it if all faculty had submitted work).
In any case the REF has kept us in mind by marshalling its raw data into none other than a spreadsheet, obtainable here:
http://results.ref.ac.uk/DownloadResults
(And yes, you’ll have to autofit the F column. Note as well that the sheet does not offer the entire-staff figures with which THE scaled its intensity-weighted GPA.)
You’ll see each department receives three sub-ratings – Outputs, Impact, and Environment (explained here), these weighted in turn (Outputs contributes 65% of the whole) and shook well into the Overall figure, the impact metric which THE reports on its pages (in effect, then, the Overall datum operationalizes impact).
If nothing else, the dataset seems to exhibit all due good form, what with its proper concern to treat as items what could have, and more troublesomely, been awarded field status (again, see my discussions of the matter in my August 22 and 29, 2013 posts). For example, the Profile field properly ingathers these items – Outputs, Impact, Environment, Overall – when a heavier hand would have parcelled them into independent fields. But a few curiosities fray the edges, nevertheless.
If, for example, you want to reconsider the data in pivot table form, well, go ahead. And when you do you’ll get here:
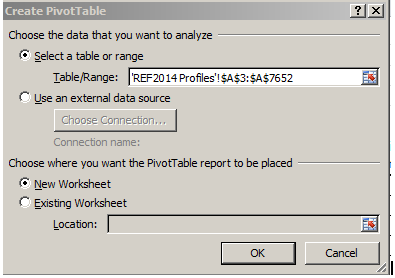
Allow me to suggest that the single-columned range requesting your OK isn’t what you’re looking for – but what’s the request doing there to begin with? Scroll about the sheet until you pull over by the merged cell L6:
![]()
And it’s that that unassuming, title-bearing text that’s jamming the table construction, by squatting directly atop the data and stringing itself to the data directly atop it in rows 3 to 5 (that latter row is hidden, and features another bank of apparent, and extraneous, field headers. I can’t quite explain what they’re doing there). Thus the contiguous data set – the warp and woof of pivot tables – starts in row 3, and the pivot table launch process regards it as such; but because its “headers” head column A only, that’s all Excel chooses to work with for starters; hence the curtailed A column range in the screen shot above. The fix of course is simply to delete the title in L6, restoring the data set’s inception to row 8 (note that because L6 is a merged cell, it takes in row 7, too).
Next, in the interests of corroboration, you may very well want to go on to calculate the sub-ratings streaming across each data row. Let’s look at the numbers in row 9, the Outputs for the Allied Health Professions, Dentistry, Nursing, and Pharmacy area at Anglia Ruskin University. The 1-4 ratings (along with unclassified, the rating set aside for work of the most wanting sort) – really field headers – patrol cels L8:O8, and so I’d enter the following in Q9:
=SUMPRODUCT(L9:P9,L$8:P$8)/100
Here the most nifty SUMPRODUCT, a deft function whose Swiss-army-knife utility is very much worth learning (and that goes for me too) multiplies paired values in L8/L9, M8/M9, etc. across the two identified ranges (or arrays, as they’re officially called) and adds all those products, before we divide the whole thing by 100, because the REF’s staff counts need to be expressed anew in percentage terms. The $ signs hold L8:P8 fast; they store the rating values, and because they do, will be brought to all the 7,500 rows below.
But if you’ve gotten this far you haven’t gotten very far at all, because you’ll be told that Anglia Ruskin’s Health Professions scholarly exertions earned that department a 0, even though THE awards it a 2.92 – and if you don’t believe that, it says so right there on page 41 of its hard copy.
Someone’s wrong, and it’s us – though with an excuse, because the REF spreadsheet has shipped its field headers in label format. 4* isn’t a number, and neither is “unclassified”. Mulitply them, and you get nothing – in our case, literally. Of course the remedy is simple – replace 4* with a 4, and so on, though it should be observed that you can leave “unclassified” alone; after all, multiply a value by 0 or by “unclassified”, and either way you get zero.
In any case, once we get it right you can copy the formula down the Q column and name its field Averages or whatever, and you’re ready to get your pivot tables in gear. But the larger, or at least the prior, question that could be rightfully asked is why the REF did what it did. It’s clear that its data stalwarts are happy to make their handiwork available to folks like us; that’s why they’ve given us a spreadsheet. How then, do we account for the little bumps in the road they’ve raised across our path? There’s nothing secretive or conspiratorial about this, of course, but the very fact that the REF averages of departmental accomplishment just aren’t there leave them to be computed by interested others. And that bit of computation could have been eased with bona fide, quantified ratings in L8:O8, and a repositioned title in L6. Those little touches would have been…excellent.

Leave a comment