Seekers after news about open data – and some of the data themselves – would do well to unstrap their backpacks at the OpenData-Aha site, a digest about what’s up in this multifarious, crackling, unbounded domain (transparency check: the OpenData-Aha has cited Spreadsheet Journalism).
Follow some of the Aha story links and the odds are highly encouraging that you’ll find yourself inside some governmental entity’s spreadsheet, e.g., the record of civilian complaints lodged against members of the Indianapolis, Indiana police force dating from July 2012 through September of last year:
Indianapolis citizen complaints
(You’ll note that the 2012 data describes incidents for July of that year only, and the 2013 complement features six, non-contiguous months of the year, for whatever reason).
The sheet, developed under the aegis of the law-enforcement data developer Project Comport, is informatively paired with a field-defining legend that should anticipate some of your questions about what the records are trying to tell us; but you’ll still need to perform a measure of house cleaning in order to neaten the dataset, e.g. the traditional column autofitting. And again – because we’ve seen this before – you may well want to cleanse the occuredDate (sic) entries of their superfluous times, all of which report midnight (the standard Short Date format dropping down from the Number Format menu in the Home ribbon would work to eradicate these). You’ll also have to contend with missing data here and there, but absent a compelling need-to-know submission to the Indianapolis police those blanks won’t go away (or at least not really, but read on). I also can’t account for the wholly unattended census tract field, which, pun unashamedly intended, remains unpopulated.
In addition, you’ll need to inspect some of the spokes in umbrella field categories such as district, which Project Comport understands as “…the District…or Branch, [my emphasis] such as Homicide or Robbery, that the officer was assigned to at the time of the incident”. Thus that field seems to subsume both locational and organizational demarcations, begging the question of how certain coding determinations in the field were finalized. For example – a complaint directed at the Covert Investigations section nevertheless and necessarily has a geographical referent – the contested event happened somewhere. By the same token, the “shift” field departs from chronology when it numbers the Crash Investigations Section among its items. We should be slightly bothered by the apples/oranges conflations here.
But a far broader conceptual concern need be confronted too, though we’ve met up with something like it in a previous post. Each complaint receives a 32-character id – but in a great many cases the complaint comprises multiple sub-complaints. Complaint 453f6ca045a7b7ea292cb3daebe83e7d, for example, evinces 12 individuated grievances filed by a 22-year-old black male against four different officers. Do we regard these multiple remonstrances in unitary or aggregated terms? In fact, the data register 407 different complaint ids among their 1,004 records, these pressing their allegations toward the 378 unique police officers represented in the officer identifier field. How are all these to be counted?
After all – if a particular officer is implicated in three offenses in the same incident, how does that plurality factor into any pivot-tabled summary? On the other hand, if the same officer is charged with the selfsame three delicts, but instead on three discrete occasions – and as such incurs three incident ids – how should that batch of events be reckoned in turn?
Of course it would be perfectly legal to try and play it both ways – to treat the data as they stand in their default, quasi-redundant id reportage for some analytical purposes, and at the same time to isolate a parameter in order to consider its entries singly.
For example – if we wanted to learn something about the demographics of officers against whom the complaints were preferred we could click anywhere in the data and conduct a Data > Remove Duplicates winnowing of the records, ticking only the last, officerIdentifier field. Go ahead, and those 378 officer records will have been pared from the source data set (I’d immediately run a Save As routine here, the better to preserve the slimmed set in a new workbook and thus leave the original data intact).
You could then try out this initial pivot table:
Row Labels: officerRace
Values: officerRace (% of Column Total; filter the four blank records; by definition they can’t help us. We also don’t need the Grand Total, and I’ve retitled the Values field name):
I get:
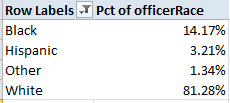
Of course, those proportions are like a stick with one end, absent comparative data of the general racial makeup of the Indianapolis police force. But those data do appear to be available, by clicking the Download Officer Demographic Information for the IMPD link here. Those police force percentages read thusly:
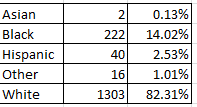
The black-white officer ratio is nearly and remarkably identical to the complaint breakouts, intimating that white officers are no more likely to be complained about (although you may want to complain about my dangled preposition).
Or by extension, one could run another Remove Duplicates at the original data, this time by checking incident id (and assuming that only one citizen is enumerated per id, a premise that appears to hold) in the interests of learning more about the age and racial identifications of complainants. But that intention is slightly weakened by the smallish but real possibility that some individuals had levelled more than one complaint; if that be the case, our duplicate removal might nevertheless count some persons multiple times. That’s because unlike the officer identifiers, each of which clearly point to a unique officer, incident ids distinguish unique events, and not the persons embroiled in them.
In any event, if we proceed with the above Remove Duplicates and indulge the assumption that each complaint id associates itself with a unique Indianapolis resident, we could try:
Row Labels: residentRace
Values: residentRace (% of Column Total; again, conceal the blanks and the Grand Total).
I get:
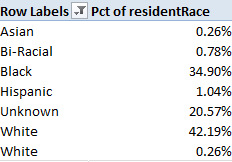
Yes, you’ve caught that superfluously-spaced White entry (the second one, totaling one record); again, you need to direct a find and replace at the delinquent datum, finding White[space] and replacing with White. One also has a right to wonder about the large Unknown bin, a proper matter for further investigation.
In any event, map the above numbers to Indianapolis’ black-resident proportion of around 28% (another source puts the number at around 24.5%) and we see the maldistribution is real but not quite overwhelming; not shocking, but surely notable.
Still, a look at all 1,004 incident records, irrespective of the doubling up of incident id, could develop other useful conclusions. After all, each of the 1,004 sub-complaints require some or other legal disposition (as identified in the “finding” field ; again, the Project Comport field legend explicates the four finding possibilities).
Now in this case, however, the blanks stand in a different relation to the empty cells in other fields. These signify complaints on which a ruling has yet to be issued, and as such might well merit counting. I’d thus select I2:I1005 (remember we’re working with all the records this time) and spin through a find and replace, finding the blank cells and replacing them with say, “Pending”.
Then a simple pivot table awaits:
Row Labels: finding
Values: finding (% of Column Total, no Grand Total)
I get:
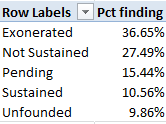
Note only 10.56% of all complaints were sustained, resulting in a definitive incrimination of an officer, though a Not Sustained judgment does require a reporting of the officer’s name to what is called the Indianapolis department’s Early Warning System.
Lots of bouncing back, them, between data sets. But I’m not complaining.

Leave a comment