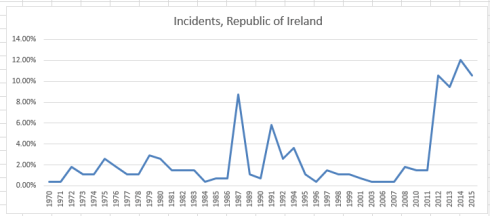
Last week’s post on the fecund Global Terrorism Database wound down with a selective look at some countries toward which popular scrutiny might be expected to be drawn, e.g., Iraq, Ireland, and Israel. But a more extensive set of drill-downs across all the data might impart some educative breadth and depth to an understanding of the terrorism phenomenon – or phenomena.
For example, by isolating five-year tranches of incident frequency we should be able to learn something about the tectonic movement of terrorist activity. We could look to this pivot table:
Rows: country_txt
Columns: iyear (grouped by units of five years)
Values: country_txt (in effect we’re really interested in the number of times a country’s name appears in the dataset; each mention of course identifies an incident).
We could then filter by tranche, e.g.:

And for presentation purposes we could right-click anywhere among the Rows data and click in turn Filter > Top 10, calling up the default top 10 items (you’ll still need to sort these results though, here Largest to Smallest. Top 10 doesn’t sort automatically, though it should).
For 1970-74, then, I get (remember to sort):

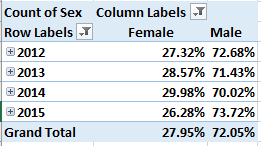
I suspect you’re surprised. Would you have imagined the United States the world’s most incident-ridden country during the above years, and the United Kingdom in second position – and with totals far greater than any other country?
But then filter for 1975-79 (again remember to sort):

The picture is sharply redrawn. We see Italy experiencing a more than twenty-fold incident spike in these five later years, and with Spain incurring ten times as many acts as in the earlier tranche. The United Kingdom remains the second most terrorized country, and the aggregate, all-nation incident total of 7,169 overwhelms the 1970-74 count of 2,668.
The outcomes take a decidedly Latin American turn in the following tranche:
Vast national changes roil this table, along with the disappearance of the United States from the top 10. Proceed with the five-year breakouts and the incident distributions swing manifestly, and here not surprisingly, to the Middle East (remember though that the absent 1993 data depress the 1990-94 counts artificially).
Now if you want to learn to whom the GTD imputes responsibility for the acts, while continuing to image the results by year and country, I’d dislocate country_txt from Rows and restore it to a Slicer. I’d next introduce gname (comprising identities of apparent perpetrators) into Rows (but you can leave Count of iyear in place in the Values area; each gname entry is associated with a year, and so counting gnames communicates nothing we can’t learn from counting iyears, which are posted to every entry).
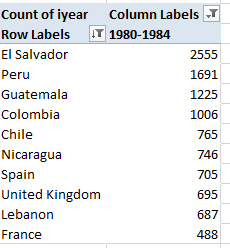
Click Italy in the slicer for the 1975-79 tranche and observe an extraordinary diffuse 120 groups implicated in at least one act, in addition to a perhaps nearly-as-startling 470 acts – 48% of all – ascribable to unknown parties, itself a researchable theme, it seems to me. Tick United Kingdom for the same period and discover that 541 of its 866 incidents, or 62.47%, are laid to the Irish Republican Army; the country’s Unknown proportion, however, amounts to a slight 1.73%. Filter for 1980-84 and tick the Slicer for El Salvador, the modal country for that parcel of time with 2,555 events, and again behold the enormous Unknown attribution, accounting for 49.08% of all incidents. Not far behind are the 1,166 attacks launched by the Farabundo Marti National Liberation Front, or FMLN, a pastiche of left-wing insurgencies that was legalized in 1992. Indeed, its incident total swelled to 1,485 in the 1985-89 tranche, then fell back to 678 in 1990-94 and recorded no acts in the 1995-1999 phase. In fact, no terrorist records appear for El Salvador after 1997.
Apropos the above, the GTD’s Region field lets us drill up to findings such as this one, for starters:
Rows: Region
Values: Region
Region (again, by % of Column Total)
I get:
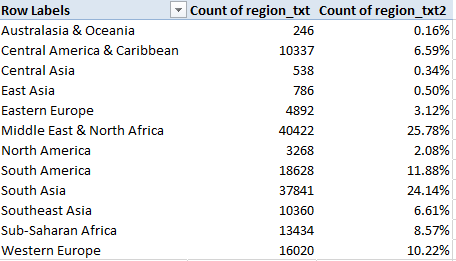
But those are coarse 45-year aggregates. Add iyear to Columns and subtract the first region column data from Values for neatness’ sake. Grouping again by five-year bundles I get:
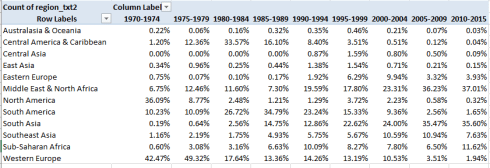
The shifts are massive and evident (and remember the percentages read downward). The early, relative vulnerabilities of North America and Western Europe’s have supplanted by the latter-day terrorist effusions of in South Asia and the Middle East, with South America’s peak in activity in the 1980-1994 swath shrinking remarkably, along with comparable abatements in North America and Western Europe. Anyone seeking a cogent charting of the political winds gusting across the globe in the past 45 years would do well to start here.
Now for a technical consideration. I’ve alluded a number of times to the missing 1993 data which, among other things, obviously undercount the 1990-94 values (and even so, the Middle East totals for the four available years in the that demaraction more than double the 1985-89 figure). One means for adjusting for the shortfall is to recalibrate the years into effective five-year partitions, e.g. 1980-84, 1985-89, 1990-95, 1996-2000, etc, an intention which should also succeed in trimming the curious, six-year 2010-15 interval back to five years; but because a given pivot table can’t (so far as I know) group values irregularly – that is, by variable intervals – we need to crack the wrapper open for Plan B, one driven by the FREQUENCY array formula, and that should allow us to break out incident totals both by years and country.
It works something like this: enter the first free column in the dataset sheet (it should be EH) and name it ccount (for country count) or something like it. Slip in a new worksheet and enter this range of year intervals down a column (I’m working in G6:G15):
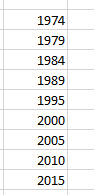
Note the six-years distancing 1995 from 1989, again a compensation of sorts for the missing 1993 data. Then enter a country name in I7 in the new sheet (I’ve started with the United Kingdom), name that mono-cellular range ctry, and enter back in the source data sheet, in EH2:
=IF(I2=ctry,B2,””)
That formula tests the country names in the I-column, country_txt field for a match with the name you’ve entered in the ctry cell. If the match avails, a 1 is posted; otherwise, nothing, as it were, is emplaced. Copy the formula all the way down EH and name the just-formed range ccount. Then return to the new sheet and select H6:H15, the cells alongside the year references. With the selection in force enter in H6:
=FREQUENCY(ccount,G6:G5)
And conclude the process with the trademark Ctrl-Shift-Enter triad befitting array formulas. The grouped incident totals for the United Kingdom should write themselves down H6:H15, commensurate with the years G6:G15. Again, note that FREQUENCY can support intervals of fluctuating width, thus enabling the counting of the five data-available years between 1990 and 1995, with each year in the G column standing for the maximum allowable year in each bin. Enter any other country in I7, and its totals should likewise break out in the respective bins.
And there’s still more to say about the GTD.