So far, the NY Election contribution data have been pleasingly mild-mannered: no scruffy labels gate-crashing the contribution and date numbers, and a candidate name field in which each and every hopeful is decorously spelled the same way.
Yet I don’t mean to sound ungrateful, but I’m bothered by those enormous unitemized receipts reported to the worksheet by the Clinton campaign. That’s not an ethical cavil, mind you, but a data-management reservation. You’ll recall that about half of all of the Democrat’s take in the state (as of July 31) has been crowded into nine massive coffers, each of course comprising one record; and those composites enter the worksheet as what are in effect subtotals (though they’re not, of course, subtotaling the other records in the set; they’re adding contributions quite external to the worksheet) – and for pivot tabling and other purposes, subtotals and individuated records in a data set don’t mix.
As suggested in the previous post, I’m not sure that any worksheet-derivable patch for the problem looms. There’s no immediate way of knowing how many Clinton sectaries have collectively added to the unitemized millions; a call to the Clinton campaign might come away with an answer, and it might not.
In light of the above you’ll recall we originally pivot-tabled an average Clinton contribution of $489.72, that figure fed and distended in large measure by those giant unitemized batches. What one could do, perhaps, is subtract their $41,815,649 from the Clinton total and divide what’s left on the sheet by the 165,504 other contributions on the books, on the assumption – quite clearly an arguable one – that the unitemized gifts approximate the others in typical size. Pursue this idea, and the resulting £231.78 more than halves the original Clinton average – for what it’s worth.
Other breakouts await, for example a cross-sectioning of contributions by candidate as well as New York zip code. Of course you’ll want to know which zip code references which place; look here for a code-by-county identification (though I’m not sure about the View Maps link aligned with each code. A click of the link for the 11390 zip in Queens drew up for me a Google Map of a region of France that, so far as I know, can’t be reached by subway).
At base, American zip codes describe themselves in five-digit terms, but you’ll see that most of the codes attached to donor provenances in the contbr_zip field (in column G) have widened to nine digits; those extra numbers comprise zip code extensions that further specify some territorial position within the ambit of the superordinate, five-digit code area. But since a useful aggregation of the contributions by codes would want to lift the analysis to the base five-digits stratum, we need to disengage the first five numbers from the lengthier entries in contr_zip. That sounds like a job for the LEFT function; thus in your next available column (mine is T; we claimed S last week for formula purposes), enter Zip Code in row 1 and enter, one row beneath:
=LEFT(G2,5)
Copy down the column and perform a Copy > Paste Values upon the results; and now what? Here’s what: we need to convince ourselves that each and every cell in T in fact returns the five characters we seek, and one means of ascertainment is this array formula, written more-or-less anywhere:
=COUNT(IF(LEN(T2:T391514)=5,1))
That is, let the array formula record a 1 for each cell in the range above whose length comes to 5, and then count all those 1s (remember that, being a customized array formula, you need to finalize the formula process by pressing Ctrl-Shift-Enter). My total of 391367 falls 146 of the field row total, pointing to that many flawed entries. If you run this one-field pivot table:
Rows: Zip Code
You’ll see on top:
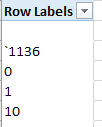
And those, needless to say, aren’t American zip codes.
In order to pinpoint those contrary 146 you can roll zip code into the Values area as well, whereby each code’s incidence will be counted, e.g.

Double-click right atop the 3 count for ‘1136, for example (yes, there’s a delinquent apostrophe in there) and all the records bearing that code will present themselves in a new sheet. We see here that all three instances are associated with Josh Rosenthal of Fresh Meadows in Queens. These are typos, of course, and a quick consult with Google tells us that the zip code for Fresh Meadows is in fact 11365. Aiming a find and replace at the data in T, by exchanging 11365 for every ‘1136, will restore Mr. Rosenthal to his proper geographical niche. On the other hand, the two “0” ersatz codes we see above both belong to Carlene Wahl of New York, and her rather generic city location will prove rather more problematic. If we want to learn her real-world zip code we’d thus need to track down Ms. Wahl and her address one way or another – if possible.
You get the idea here. We see that some, but not necessarily all, of the mis-coded 146 should be agreeable to some standard rectification; and one supposes the disagreeable ones could be filtered out of any table, if we had to.
In any case, and acknowledging the above sticking point that adheres to but .037% of all contributions, we could proceed with this table, which again organizes contributions by candidate and zip code:
Rows: Zip code
Columns: cand_nm
Values: Contb_receipt_amt
The reading here is dense, of course, but you’ll at least note the large Clinton sums piled up in zip codes beginning 100, all of which are sited in Manhattan. But look at her results for code 10185: 41,820,648.76. 10185 is likewise a Manhattan code, and here it references the address at which all those unitemized contributions were gathered.
Sound familiar, no? Kind of, because that gigantic sum, administered by the Hillary Victory Fund, has doubtless processed donations from individuals who live all over the place – zip codes unknown, and possibly unknowable.
And as a matter of fact, how do we know that all of those contributors even live in New York?

Leave a comment