There’s plenty to learn from the feature-rich Cook County sentencing dataset, and so let the learning commence. We could, by way of first look at the data, examine what the set calls SENTENCE_TYPE, a self-evident header whose entries could be additionally broken out by another field, SENTENCE_DATE:
Rows: SENTENCE_TYPE
Columns: SENTENCE_DATE (grouped by year; see the previous post’s caution about the date-grouping challenges peculiar to these data.
Values: SENTENCE_TYPE (% of Column Total, as you turn Grand Totals off for the table’s column, which must necessarily come to 100%.)
I get:

(Bear in mind that the numbers for the 2010 and 2018 are very small, a concomitant of their fraction-of-the-year data representation.) Not surprisingly, Prison – the lengths of its terms unmeasured in this field, at least – accounts for the bulk of sentences, and rates of imprisonment verge towards virtual constancy across the represented years.
Probations, however, describe a bumpier curve, peaking in 2014 but exhibiting markedly lower proportions in both 2010 and 2018 (to date). Those wobbles, doubtless both statistically and criminologically significant, call for a look beyond the numbers we have.
I’ve been unable to turn up a denotation for the Conversion sentence type, but I can state that the zeros, first appearing in 2011, are actual nullities, and not an artifact of the two-decimal roundoff. Slightly more bothersome to this layman, though, was the Jail sentence; I didn’t know if that event discreetly named a particular mode of punition, or merely, and wrongly, reproduces Prison sentences under a second heading. It turns out that the former conjecture is in point, and that jail time is typically imposed for shorter sentences or individuals awaiting trial (see this clarification, for example. For an explication of the Cook County Boot Camp, see this piece).
The natural – and plausible – follow-on would associate sentence types and their distributions with types of crimes, but the presentational challenge proposed by a keying of the sentences to more than 1500 offense titles very much calls for a considered approach, indeed, one that could perhaps essayed with a Slicer populated with the offense titles. And while that tack will “work”, be prepared to scroll a long way until the offense about which you want to learn rises into the Slicer window. But such is the nature of the data.
And in view of that profuseness one could, perhaps, engineer a more practicable take on the matter, for example, by inaugurating a new pivot table, filling the Rows area with say, the top 20 offense types (right-click among Rows and click Filter > Top 10, entering 20 in the resulting dialogue box). Sort the types highest to lowest, line the Columns area with the Sentence Types, drop Offense_Type again into Values, and view them via the % of Column Total lens.
A screen shot here would be unacceptably fractional in view of the table’s width, but try it and you’ll see, for example, that 93.41% of the convictions for unlawful use or possession of a weapon by a felon resulted in a prison sentence, whereas perpetrators guilty of theft – however defined in this judicial context – incurred prison but 36.41% of the time, along with a 45.69% probation rate.
More troubling, however, is the small but measurable number of death sentences that appear to have been imposed on individuals sentenced for crimes not typically deemed capital. For example, .04% of the convictions for the possession of cannabis with intent to deliver/delivery of cannabis have drawn the death penalty, as have .05% of forgery convictions. These legal reprisals don’t ring true, and surely obligate the journalist in a redoubled scrutiny, if only to confirm their accuracy, and/or their propriety.
If you’re looking for other fields to irrigate, sentence length, expressed here as COMMITMENT_TERM, likewise begs for correlation with other fields; but here a new roadblock stalls the journey. Inspect the field and the adjoining COMMITMENT_UNIT column and the obstruction will loom large. Because the units present themselves in a raft of different durations, the correlations can’t proceed until some manner of unit reconciliation is brought to the data.
My early sense about the COMMITMENT_UNIT field told me that the disparities merely juxtaposed years to months; and were that the case, a simple formula could be stamped atop an new field, one in which either years could in effect be multiplied by or months divided by that value, e.g. a six-year sentence could be translated into 72 months.
But in fact, the units are a good deal more numerous and qualitatively varied than that. Turn a filter on the data set and click the arrow for COMMITMENT_UNIT. You’ll see:
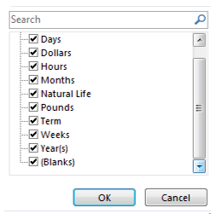
While it would be possible to construct an equivalence lookup table for the chronological units enumerated above, e.g., one month rephrased as 720 hours, a sentence delivered in monetary terms – dollars – can’t be subjected to a like treatment. And a sentence of Natural Life – presumably an indefinite, open-ended prison stay – is similarly unavailable for equating. Moreover, I have no idea what the two records declaring sentences of “pounds” – 30 of them for a criminal trespass of a residence, and 2 for driving with a suspended or revoked license, and both pronounced in Cook County District 5 – Bridgeview – can mean. And you may note that 19 sentences comprising 365 days each were issued as well; how these distinguish themselves from one-year terms is unclear to me. Nor do I understand the 1526 sentences consisting of what are described as Term.
On the one hand, of course, the data set can’t be faulted for admitting all these “discrepancies” into its fold; they’re perfectly valid and pertinent records. On the other hand, they cannot, by definition, be forced into comparability with the other entries; they’re oranges to the predominating crop of apples.
The simple way out, of course, would be to sort out and excise the non-chronologicals and proceed, and on a blunt practical level that stratagem might work. But it would work here for the simple empirical reason that those incongruities are few, and as such, would not compromise the greater body of data. But what if these irregulars were formidably populous, and hence unavoidable? What would we do with them?
That is a good and interesting question.

One Response to “The Verdict on Cook County Court Sentencing Data, Part 2”