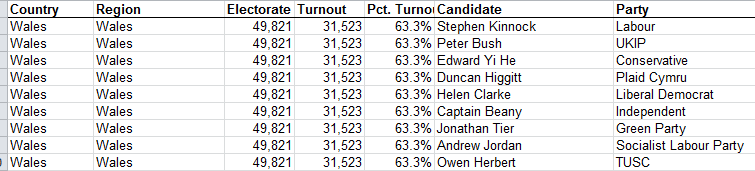
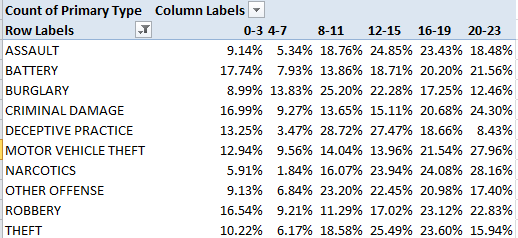
School bullying is a serious business, of course, and data on this devastating social practice need be treated with all due sobriety. Some cheering, current information on the matter finds incidence down in US, at least, and for a state-specific look, the education department of the American state of Iowa makes its data on bullying available to you and me on its www.educateiowa.gov site. Its latest of its spreadsheets counts instances for 2011-12 and awaits here:
You’ll note the tabs detailing bullying allegations directed at both staff and students, and still a third sheet recalling a single, racially-motivated incident aimed at a Volunteer, whom I take to be an individual who had devoted some free time to a school in the Davenport Community School District. Clicking into the STUDENT sheet you’ll discover the incident data pulled apart into Public and Non-Public school tranches, a decision I would have overruled (you’ll be pleased that my name is nowhere to be found among the cards in Iowa’s official rolodex), consolidating instead all the records into a unitary dataset boosted by a School Status field, with institutions receiving the Public or Non-Public tag. That revamp of course would facilitate useful pivot-tabled breakouts along those lines, and in fact the deed can be done easily enough (though for purposes of exposition below I’m simply respecting Public and Non-Public’s separate spaces as they stand) ; dub H5 School Status, enter Public in H6 and copy down to row 1063 (just double-click the autofill button). Then delete rows 1063 to 1065 (that first-mentioned row offers grand totals, its retention subjecting any future pivot table to a double-count), enter Non-Public in what is now 1063, and again copy down, remembering again to delete the now-1192 and its Non-Public grand totals.
Note as well the cell-merged Public header leaning atop the data in row 4. That needs to be sent away,, either through deletion or by the interposition of the ever-reliable blank row.
And there’s something else: because we’ve taken over the H column we suddenly need to do something about the Total field in I. That field’s school-by-school, row-driven totals had been nicely distanced from their contributory data by the heretofore blank H, heading off yet another double-count prospect. The question is what to do about it.
I’m posing the question because the by-the-book counsel, the one in fact endorsed not three paragraphs ago, is to dismiss total rows and their odious double-count potential. The problem here, though, is that the types of bullying the data consider, e.g. Physical Attributes, etc., are each accorded a field all their own – and if you want for example to total all bullying instances for a school you can’t pivot table them into the very standard Summarize Values by Sum recourse. You can’t – again – because Summarize Values works upon the numbers in one field, and not the values across fields. We’ve sounded this concern many times (e.g. the August 29, 2013 post), in part because it does require repeating soundings.
Thus the data set’s first record:
![]()
Would ideally have been properly dispersed thusly:
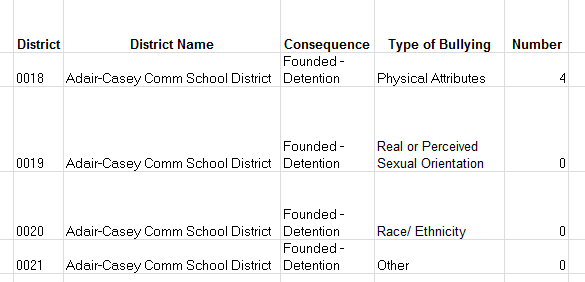
Again, by downgrading each bullying type from its independent field status to an item in a larger, subsuming field, standard totalling, and other, no-less-standard operations (e.g. % of Row), resolve into practicability. Thus in the case before us we might as well retain the existing totals, because we’d need to manufacture them anyway, through a messy calculated field or…a Total column in the data set that’s already there.
If, then, for illustration’s sake we do retain the services of Total, we can go on to at least break out all bullying (Public school) occurrences by district:
Row Labels: District Name
Values: Total (Sum, and sorted by Largest to Smallest).
District Name (Count)
In excerpt I get
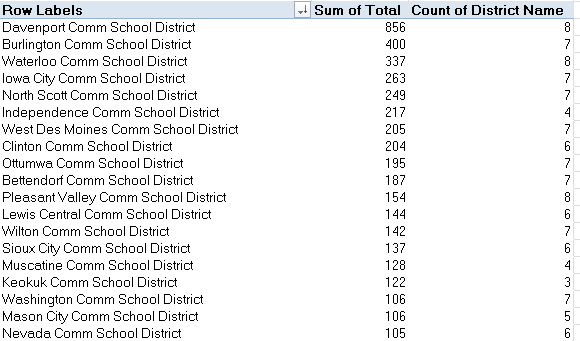
It was the Davenport (public) School District that suffered by far the largest number of reported – repeat, reported – bullying episodes, but absent any control for district size the analysis stalls here, though the numbers are instructive nevertheless. Doing the same to the Non-Public districts (and remember that if you’ve left the Public and Non-Public data as you found them you’ll of course require a header row for each) I get (again, the screen shot is fractional):
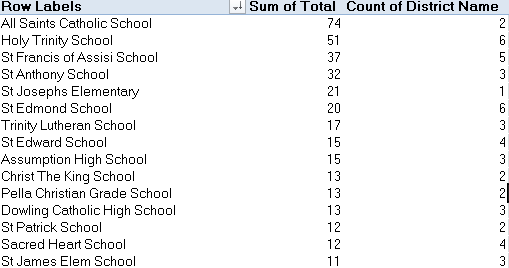
Far fewer reports visit the table, though I suspect the districts above are notably smaller. If they in fact aren’t, we’d then need to think about willingness to report and school decorum across institutions and districts. In short, the data don’t yet read definitively, but they supply the goad for additional researches.
Then there is the matter of what the Iowa calls report Consequence. The public school data set counts nine of these:

The consequences critically dichotomize the reports into Founded and Unfounded allegations, with a pair of residual Consequences items filling in some of the blanks. It thus seemed to me that a global breakout along Founded/Unfounded lines would do much to inform an understanding of the reports. I’d thus take over the next free column (probably I or J, depending on whether you’ve adopted the School Status field), call it Report Status, and enter in the next row down:
=IF(LEFT(C6,12)=”Consequences”,”Consequences”,LEFT(C6,FIND(“-“,C6)-2))
What is this expression saying? It’s propounding an IF statement that asks if the first 12 characters of any entry in C contain that very word – consequence. If so, the formula returns it. If not, the statement looks for the character position of the “-“, subtracts 2 (where the pre-hyphen text in such cells would terminate), and lifts those characters into the cell. In this latter case, either Founded or Unfounded should turn up.
Once we’re happy with its workings copy the formula down C. You can then pivot table, on the public school data:
Row Labels: Report Status
Values: Report Status (Count, Show Values As > % of Column Total.
(Again, you don’t want Grand Totals; of necessity they’ll return 100%.)
I get
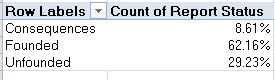
That’s informative. Executing the same routine for the non-public districts:
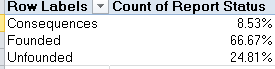
Far fewer cases here, to be sure, but when reported, the charges seem to exhibit slightly more traction. Note also the near-identical Consequences percentages.
As earlier conceded, our looks at the bullying reports may supply some of the necessary, but insufficient, conditions for any conclusive take on the problem. But necessary.