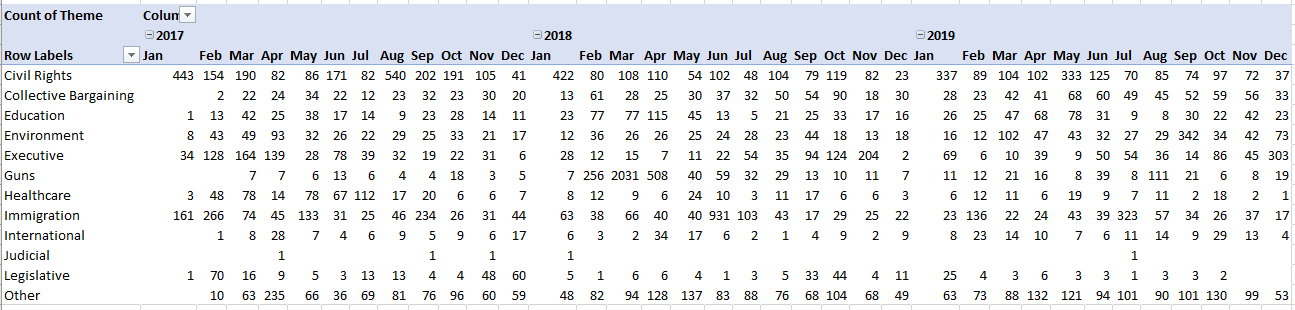
The data are incomplete, but if you want to learn something about gender skew in the art world while cutting your teeth on Excel’s new dynamic array functions at the same time, then book a viewing here:
https://github.com/MuseumofModernArt/exhibitions
(Click the green “Clone or download” button and call up MoMADirectorsDepartmentHeads.csv from the resulting zip file).
You’ll be brought face-to-monitor to a catalog of installations curated by New York’s Museum of Modern Art, and chronologized from the museum’s inception in 1929 through 1989. The data have been expounded here by Anna Jacobson, of the curiously-named UC Berkeley School of Information (one would like to think all schools disseminate information, but I do go on). Jacobson details the markedly pinched proportion of women artists who’ve threaded their way among the exhibitors, via a series of tabular and charted corroborations.
And while I’m not sure what application helped guide Jacobson through her trek across the data I can say with uncharacteristic certainty that it wasn’t the dynamically-arrayed Excel; that’s because, September 2018 curtain lift nothwithstanding, the general release of the upgrade was vamped-till-ready until this January – and then only for Office 365 users.
But’s it’s here, at last, and the MoMA data cultivates a fertile staging ground for a first look at the dynamic-array complement, in part because the records bare numerous redundancies among the entries, e.g. repeated Exhibition titles; and compacting redundant data into a uniques-only set has stuck in the craw of Excel users like an Excalibur jammed into its stone.
Of course ways through the problem have already been charted, which we earlier encountered here, for example. We can now, for instance, apply Pivot Tables’ Distinct Count to the challenge; but the dynamic array alternative has it beat.
By way of demonstration, I first streamed the dataset through the ancient Create from Selection command, thus field-naming each column per its header. I next inaugurated a new worksheet and entered somewhere, say in I6:
=UNIQUE(ExhibitionTitle)
I got, in excerpt:
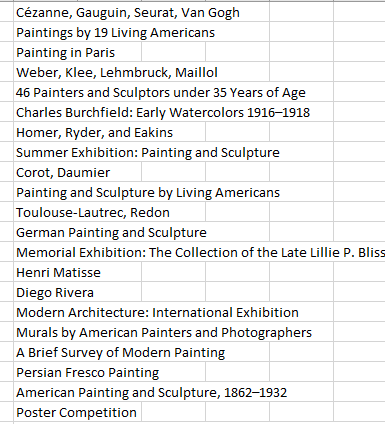
We’re viewing the game-changer. Here, and for the first time, Excel enumerates the elements of an array that would have heretofore been trapped inside an array formula:
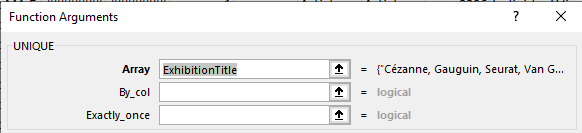
We now see, in their respective cells, the singular disclosure of each and every exhibition – all propagated by a solitary formula, the one in I6.
And we could proceed:
=SORT(UNIQUE(ExhibitionTitle)
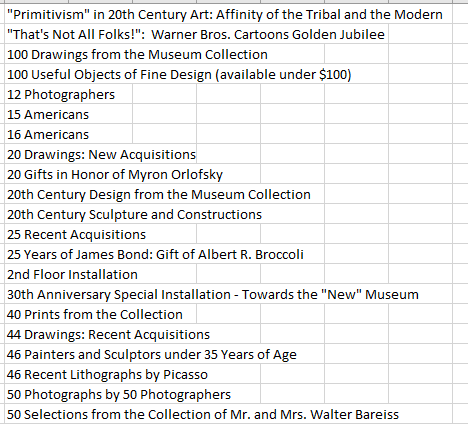
Cool, simple, and trenchant. And for a simple unique count, try:
=COUNTA(UNIQUE(ExhibitionTitle))
I’ve thus learned that 1664 different exhibitions held down a space at MoMA – this from a dataset comprising 34559 records.
And now about those gender ratios: The worksheet’s Gender field lends itself to a number of informing looks, e.g, a simple, traditional COUNTIF-driven look at the women/men divide:
=COUNTIF(Gender,”Female”)
=COUNTIF(Gender,”Male”)
The respective aggregates: 2,527 and 23,269, a disparity needing to recognize the nearly 25% of the Gender cells that are unfilled (note that Jacobson’s dataset discloses a blanks count of around 15%.) In any case, we learn that more than 9.2 times as many men are represented among the exhibitors than women – maybe. I’m equivocating for two reasons: first, the ExhibitionRole field names seven statuses by which an individual could be described, only one of which is Artist (in addition to the Blanks residual category); and while the great majority of entries are so identified, an exclusion of the non-Artist entries need be imposed, and via the following refinement:
=COUNTIFS(Gender,”Female”,ExhibitionRole,”Artist”,ConstituentType,”Individual”)
=COUNTIFS(Gender,”Male”,ExhibitionRole,”Artist”,ConstituentType,”Individual”)
(Jacobson points out that Constituent Type need be lowered into the formulas, as a handful of Institutions entries in the field are associated with the Male item in Gender.)
Now I total 2,301 and 22,507, returning an even higher male/female disparity of 9.8.
Telling and instructive to be sure, but alternative takes on the data are there for the taking. We haven’t, for example, distilled the data into unique compendia of men and women artists, in which each exhibitor is accounted for but once; and once realized, those outcomes could likewise be submitted for comparison.
If that’s what you want, this formula would appear to deliver:
=COUNTA(UNIQUE(FILTER(DisplayName,(Gender=”female”)*(ExhibitionRole=”Artist”)*(ConstituentType=”Individual”))))
That dilated expression needs to be explained, of course. Here we’ve rolled out the powerful dynamic-array FILTER function, enwrapped both by UNIQUE and the old favorite COUNTA.
FILTER asks two essential questions, embodied in its two required arguments: what field (fields) is to be filtered, and by what criteria? Thus
=FILTER(DisplayName,Gender=”Female”)
Will succeed in returning – that is, unroll down a column – all the names in the DisplayName field associated with the “Female” entry in the Gender field. But that’s an example. Our expression here will hinge its yield on three criteria – the appearance of Female in Gender along with the incidence of the Artist entry in ExhbitionRole and Individual in ConstituentType; and to cut a longish story short, the syntax above means to assign the value of 1 to each instance of Female, Artist, and Individual. When all conditions are met in a given record/row the three 1’s are multiplied, and the resulting 1 instructs the formula to display the associated DisplayName. But if even one of the conditions disqualifies itself – say if an entry of Male populates a Gender cell – that expression returns a 0. Multiply 1 by 0, for example – and the asterisk actually does multiply the three values – and the ensuing 0 knocks out that DisplayName from the filter.
And all that means that
=FILTER(DisplayName,(Gender=”Female”)*(ExhibitionRole=”Artist”)*(ConstituentType=”Individual”)
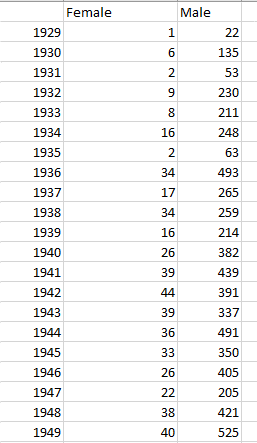
will develop this list, in excerpt:
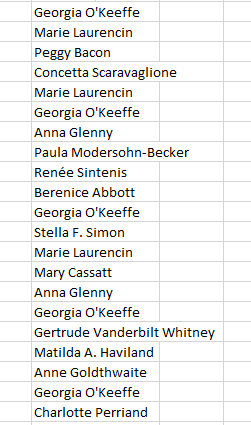
But the list is overpopulated. Note the five iterations of Georgia O’Keeffe, for example; they’re there because we’ve filtered for all instances of the women artists who’ve exhibited at MoMA. But we want to see each name once, an intention that calls for this expression:
=UNIQUE(FILTER(DisplayName,(Gender=”Female”)*(ExhibitionRole=”Artist”)*(ConstituentType=”Individual”)))
That works, but we’re not done – because we want to count that total, via:
=COUNTA(UNIQUE(FILTER(DisplayName,(Gender=”female”)*(ExhibitionRole=”Artist”)*(ConstituentType=”Individual”))))
That lengthy but intelligible construction yields 671, the number of distinct women whose work featured at MOMA between 1929 and 1989. Substitute “Male” in the Gender argument, and the sum identifies 4317 different men who exhibited during that span. The male-female quotient – 6.4 – overwhelmingly favors the former, of course, but at a notable pull-back from the earlier ratios we cited – the ones comparing all installations for all artists.
And how do these findings compare with Jacobson’s measures? I’m bidden to ask the question at all because her numbers are different. First, as observed above, Jacobson’s set presents a richer Gender field, in which only 15% of its cells are unfilled. She also went on to literally fill in some of the blanks via internet searches and first-name inferences. She reports, then:
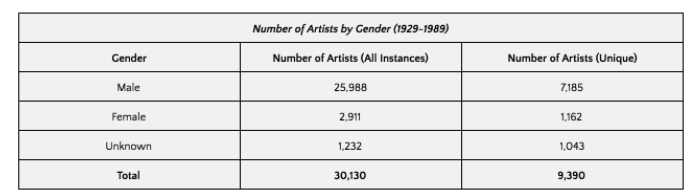
And so the comparison reads:
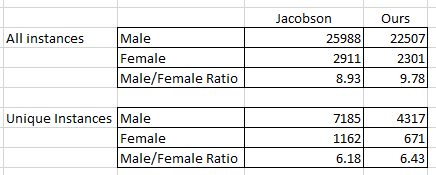
Jacobson’s reckonings are actually the more “favorable” to women, recalling our discrepant data counts.
In any event all this art talk has gotten me inspired. I’m thinking about crowd funding an exploratory budget for a Museum of Spreadsheets, a place where practitioners of the number-crunching arts can hang their workbooks in a back-lit setting befitting their craft, and with wings devoted to portraits and landscapes, and those just-discovered VisiCalc antiquities.
The first show: 21st Century Format Painters.