Charles Kurzman studies terrorists. Among other things, to be sure; a professor of sociology at the University of North Carolina at Chapel Hill and a co-chair of the Carolina Center for the Study of the Middle East and Muslim Civilizations, Kurzman knows whereof he speaks about that deadly cadre; and among the pages on his Kurzman.unc.edu web site he’s filed a Muslim-American Terrorist Suspects and Perpetrators spreadsheet, a three-tab chronicle annotating the names and activities of that particular demographic and kindred organizations dating from the 9/11 inception point through January 29 of this year. It’s available for download here:
While of course the sheet’s contents are key, the medium is what it is, i.e. a spreadsheet , and as such calls for a consideration of its data in the terms appropriate to it, particularly if you want to take the analysis forward. First note the field header’s resolutely vertical alignments, those spires constructed via this perpendicular format:

You may find readability compromised as a result; I’d have tried a Wrap Text alternative, which, if nothing else, would grant you the zoning variance to lower all those towering row heights.
I’d also call some attention to the failure of the sheets to apply stand column autofits to the entries protruding into the cells to their immediate right. In addition, the Data as of February 1, 2012 header in A1 of the Support for Terrorism sheet doesn’t quiet square with Year of Indictment data in column D that extend through 2014. And I’d also left-align the sheet’s centered text-bearing cells, in the service of additional clarity.
Turning to more substantive possibilities, a breakout of the Violent Plots suspects by age (and with the exception of three Unkowns, each record uniquely identifies an accusee) should prove instructive; but the Under 18 entry in cell S219 for an unnamed minor suspect blocks the Group Selection process, should you be interested in bundling the ages. You could, then, replace that textual legend with a 0 and filter it out of the table, e.g.
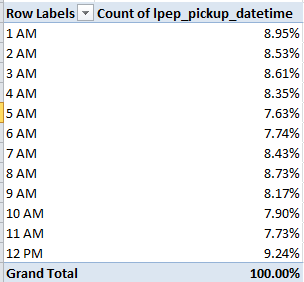
Row Labels: Age at time of arrest/attack
Values: Age at time of arrest/attack (Show values as % of Column Total)
Group the Ages into bins of say 3 years each, tick away the <0 and 0-2 groupings, and you’ll see

That more than half of the suspects fall into the 26-or-under class should be little cause for surprise, but the reciprocal, pronounced fall-off in the post-32 cohort may tell us something about the swiftness by which the appeal of terrorist causes attenuates – perhaps. (The contrastingly spotty Age at time of indictment data in the Support for Terrorism, along with a similar data shortfall for other parameters on the sheet, is noteworthy.)
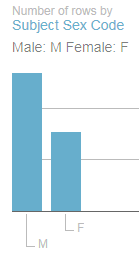
The Sex distribution of suspects,
Row Labels: Sex
Values: Sex (Count, of necessity; the field is textual)
with its sharp incline towards a 96% male representation, is again not arresting. But the breakout for the Engaged in Violent Act/joined fighting force field data, realized by dropping that field into both the Row Label and Values area, yields a 74% No reading that might be worth a rumination or two. Remember of course that the sheet notates the apprehensions for terrorist plots, which, as a matter of approximate definition, would appear to preempt those lethal designs that had in fact been carried out. Indeed, the large proportion of official charges set down in the E column that point to conspiracies or attempts validate that surmise.
And what of the targets of the plotters?
Row Labels: Target of plot/location of violence
Values: Target of plot/location of violence
I get:

Remember that the workbook devotes its scrutiny to American-based terrorist suspects, even as we see that about 40% of the plots targeted foreign sites. The substantial None figure needs to be researched, however, and a data-entry discrepancy appears to have beset the US & Abroad/US, Abroad items. I’d run a find and replace on one of the two, replacing it with the other.
As for case status, the pivot table deployment of the Status of Case field in both Row Labels and Values turns up some slightly idiosyncratic “Charged” results, e.g. “Charged in absentia; convicted in Yemen of separate terrorist act”. One could as a result move into the next available column (AS), call the imminent field Status, and enter in A2:
=IF(LEFT(F2,7)=”Charged”,”Charged”,F2)
And copy down. You’ll end up with 39 Charged entries now, which might mark out that category with both more and less precision, as it were.
The standard Convicted status shows but 66 such outcomes (plus two convicted in court martials and one in Yemen), or but 26.4% of the data set. However, an additional 112 suspects who pled guilty brings the overall incrimination total to over 70%.
In any case, with so many fields in the Violent Plot sheet, more interesting findings await.